Utilisation de réseaux existants#
Nous présentons dans la suite quatre réseaux profonds classiques. Nous montrons ensuite comment les utiliser directement, ou comment les adapter pour répondre à une problématique précise, en lien avec leur utilisation originale ou non. Nous introduisons enfin une manière d’apprendre un réseau à partir de peu de données.
Quelques réseaux profonds classiques#
Les réseaux présentés ici ont prouvé leur efficacité, notamment lors des compétitions organisées depuis 2010 sur une base de données d’images nommée ImageNet. Initiée à l’Université de Stanford, cette base de données comporte aujourd’hui plus de 14 millions d’images, classées en 21841 catégories (avions, voitures, chats,…). Dans les compétitions ILSVRC ( ImageNet Large Scale Visual Recognition Challenge), les chercheurs se voient proposer une extraction de 1,2 millions d’images d’entraînement, 100 000 images de test et 50 000 images de validation, catégorisées en 1000 classes. Le gagnant est celui qui atteint la meilleure précision de reconnaissance sur les 5 premières classes (top-5).
La Fig. 40 donne un aperçu des performances de plusieurs réseaux profonds suivant cette métrique.
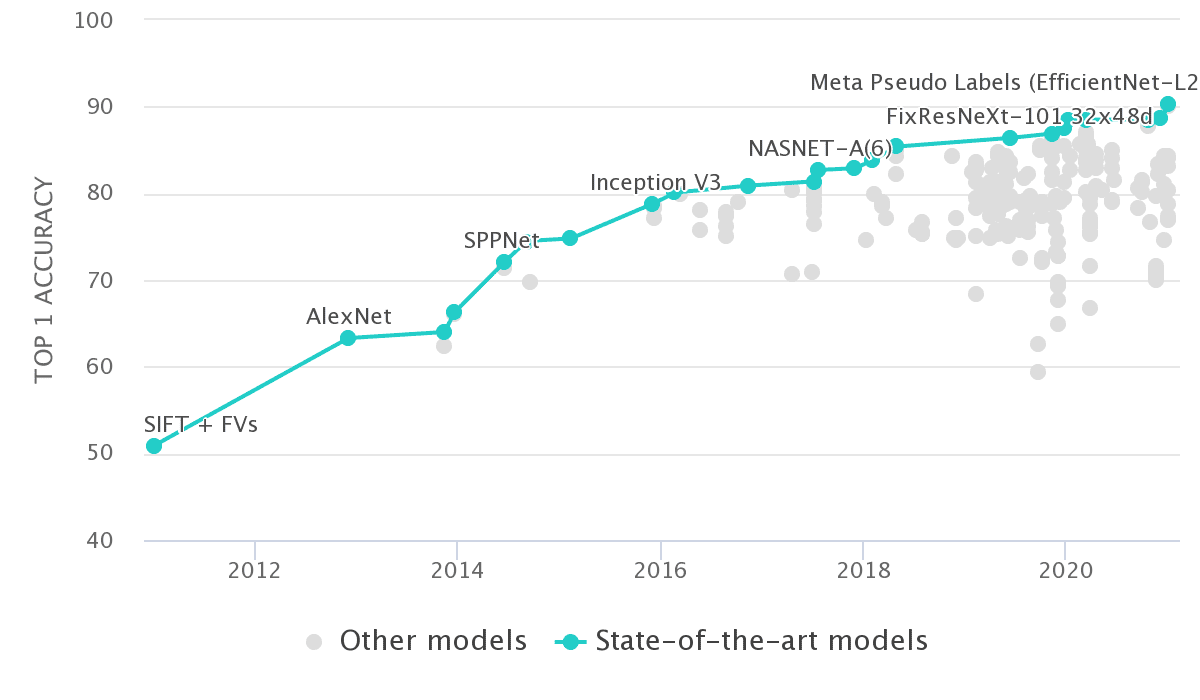
Fig. 40 Performance de réseaux profonds sur une tache de classification (source)#
AlexNet#
En 2012, Krizhevsky et al [1] remportent ILSVRC avec un taux de reconnaissance de 84.6%, en utilisant AlexNet, un réseau convolutif composé de 5 couches de convolution et de pooling, suivies de 3 couches complètement connectées (Fig. 41).
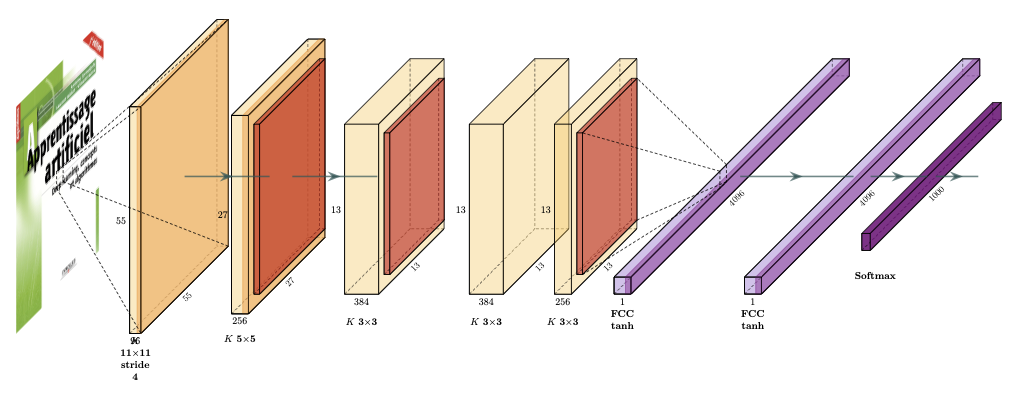
Fig. 41 Architecture du réseau AlexNet. Les couches de convolution et d’activation sont en orange clair, les couches d’agrégation en orange foncé. Les couches complètement connectées sont en violet.#
Si la profondeur du réseau reste faible, le nombre de paramètres était déjà important. En regardant uniquement la première couche de convolution, on constate que :
l’entrée est composée d’images 227\(\times\)227\(\times\)3
les filtres de convolution sont de taille 11
le pas de convolution (stride) est de 4
Ainsi la sortie de la couche de convolution est de taille 55\(\times\)55\(\times\)96=290 400 neurones, chacun ayant 11\(\times\)11\(\times\)3=363 poids et un biais. Cela implique, sur cette couche de convolution seulement, 105 705 600 paramètres à ajuster.
Ce réseau, amélioration d’un réseau existant (LeNet), apportait de nombreuses contributions, comme l’utilisation de couches ReLU, de dropout, ou du GPU (NVIDIA GTX 580) pendant la phase d’entraînement.
VGG#
Les réseaux VGG (Visual Geometry Group, université d’Oxford) [2] ont été les premiers réseaux à utiliser de petits filtres de convolution (3\(\times\)3) et à les combiner pour décrire des séquences de convolution, l’idée étant d’émuler l’effet de larges champs réceptifs par cette séquence. Cette technique amène malheureusement à un nombre exponentiel de paramètres (le modèle entraîné qui peut être téléchargé a une taille de plus de 500 Mo). VGG a concouru à ILSVRC 2014, a obtenu un taux de bonne classification de 92.3% mais n’a pas remporté le challenge. Aujourd’hui VGG et une famille de réseaux profonds (de A à E) qui varient par leur architecture
| A | A-LRN | B | C | D | E |
|---|---|---|---|---|---|
| 11 couches | 11 couches | 13 couches | 16 couches | 16 couches | 19 couches |
| Entrée : image 224×224 RGB | |||||
| conv3-64 | conv3-64 | conv3-64 | conv3-64 | conv3-64 | |
| LRN | conv3-64 | conv3-64 | conv3-64 | conv3-64 | |
| max pooling | |||||
| conv3-128 | conv3-128 | conv3-128 | conv3-128 | conv3-128 | |
| conv3-128 | conv3-128 | conv3-128 | conv3-128 | ||
| max pooling | |||||
| conv3-256 | conv3-256 | conv3-256 | conv3-256 | conv3-256 | |
| conv3-256 | conv3-256 | conv3-256 | conv3-256 | conv3-256 | |
| conv1-256 | conv3-256 | conv3-256 | |||
| conv3-256 | |||||
| max pooling | |||||
| conv3-512 | conv3-512 | conv3-512 | conv3-512 | conv3-512 | |
| conv3-512 | conv3-512 | conv3-512 | conv3-512 | conv3-512 | |
| conv1-512 | conv3-512 | conv3-512 | |||
| conv3-512 | |||||
| max pooling | |||||
| conv3-512 | conv3-512 | conv3-512 | conv3-512 | conv3-512 | |
| conv3-512 | conv3-512 | conv3-512 | conv3-512 | conv3-512 | |
| conv1-512 | conv3-512 | conv3-512 | |||
| conv3-512 | |||||
| max pooling | |||||
| Couche complètement connectée 4096 neurones | |||||
| Couche complètement connectée 4096 neurones | |||||
| Couche complètement connectée 1000 neurones | |||||
| Classifieur softmax | |||||
Le nombre de paramètres (en millions) pour les réseaux de A à E est 133, 133, 134, 138 et 144. Les réseaux VGG-D et VGG-E sont les plus précis et populaires.
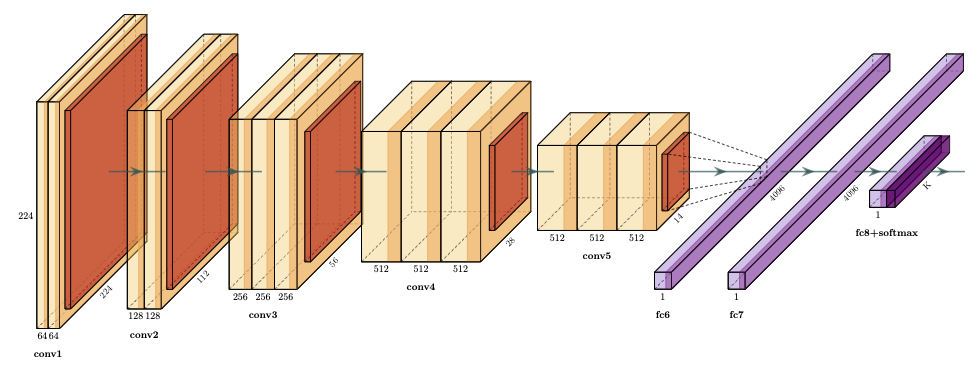
Fig. 42 Réseau VGG16#
Inception#
Inception, proposé par Google, est le premier réseau dont les performances ont été augmentées non seulement en augmentant le nombre de couches, mais en pensant et optimisant le design et l’architecture. L’idée est ici d’utiliser plusieurs filtres, de tailles différentes, sur la même image et de concaténer les résultats pour générer une représentation plus robuste.
Inception n’est pas un réseau, c’est une famille de réseaux : Network in Network [3], Inception V1 [4], Inception V2 [5], Xception [6],…
L’idée du premier réseau (Fig. 43) est de connecter les couches de convolution par des perceptrons multicouches, introduisant des non linéarités dans les réseaux profonds. Mathématiquement, ces perceptrons sont équivalents à des convolutions par des filtres 1\(\times 1\) et gardent donc la cohérence des réseaux. Cette nouvelle architecture rend moins indispensable les couches complètement connectées en fin de réseau. Les auteurs moyennent spatialement les cartes finales et donnent le résultat au classifier softmax. Le nombre de paramètres est alors réduit, diminuant de ce fait le risque de sur apprentissage.
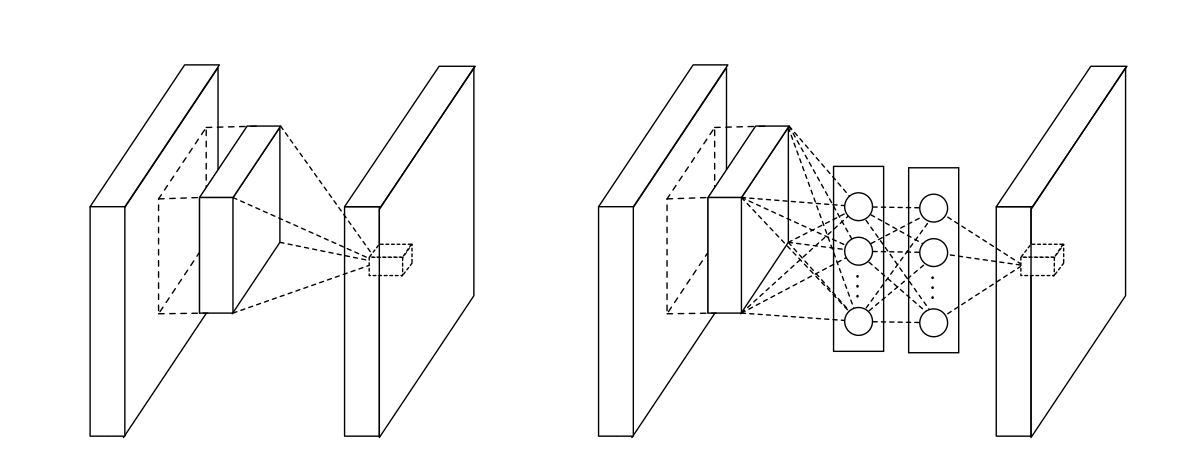
Fig. 43 Réseau Network in Network#
Inception V1, implémenté dans le réseau GoogLeNet vainqueur d’ILSVRC 2014, est une extension à des réseaux plus profonds de Network to Network. Le réseau est composé de 22 couches et atteint 93.3% de taux de reconnaissance. D’autres améliorations théoriques (fonctions de pertes associées aux couches intermédiaires dans la phase d’apprentissage, introduction de caractères épars dans le réseau) ont également permis d’améliorer les performances (de calcul et de classification).
Inception V2, puis V3 (Fig. 44) adoptent des techniques de factorisation (toute convolution par un filtre de taille plus grande que 3\(\times\) 3 peut être exprimée de manière plus efficace avec une série de filtres de taille réduite) et de normalisation pour améliorer encore les performances.
Inception V4 [7] propose une version rationalisée, à l’architecture uniforme et aux performances accrues.
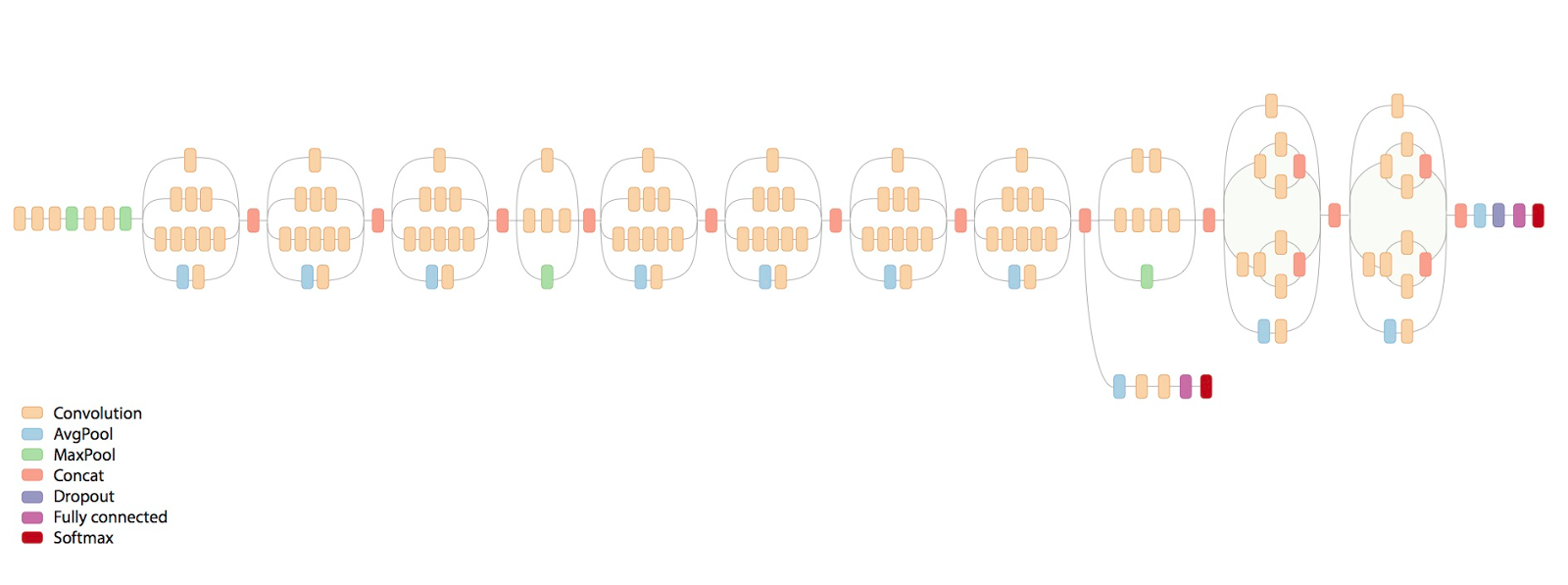
Fig. 44 Architecture d’inception V3#
ResNet#
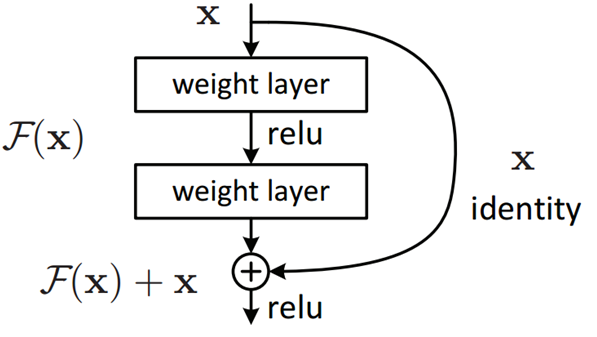
En 2015, Microsoft remporte la compétition ILSVRC avec ResNet [8], un réseau à 152 couches qui utilise un module ResNet. Le taux de bonne reconnaissance est de 96.4%. Un réseau résiduel (ou ResNet) résout le problème de vanishing gradient de la manière la plus simple possible, en permettant des raccourcis entre chaque couche du réseau. Dans un réseau classique, l’activation en sortie de couche est de la forme \(y=\sigma(x)\), et lors de la rétropropagation, le gradient doit nécessairement repasser par \(\sigma(x)\), ce qui peut causer des
problèmes en raison de la (forte) non linéarité induite par \(\sigma\).
Dans un réseau résiduel, la sortie de chaque couche est calculée par
\(y=\sigma()+x\), où \(+x\) est le raccourci entre chaque couche, qui permet
au gradient de transiter directement sans passer par \(\sigma\).
Cette représentation donne l’idée générale, mais la réalité est un peu
plus complexe, et prend la forme d’un module ResNet (Fig. 45).
Implémentation#
On propose ici d’implémenter deux stratégies :
une première d’entraînement d’un réseau en initialisant les poids à ceux du même réseau préentraîné sur ImageNet. Une couche de classification spécifique au problème est ajoutée, et tout le réseau est entraîné.
une seconde (Fig. 46) qui remplace le réseau de classification du réseau préentraîné par un nouveau réseau de classification, dont les poids sont entrâinés sur la nouvelle tâche. Les poids du réseau initial (hors couche de classification) sont conservés (le réseaux convolutif agit donc comme un extracteur de caractéristiques)
L’objectif est d’apprendre un réseau à reconnaître des images de bananes, tomates, pizza et sushis.
import numpy as np
import matplotlib.pyplot as plt
import os
from tempfile import TemporaryDirectory
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms
On utilise une technique d”augmentation de données pour augmenter la taille de la base d’entraînement. On normalise les images d’entraînement et de validation.
data_transforms = {
'train': transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = './data'
batch_size = 4
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=6) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = "cuda" if torch.cuda.is_available() else "cpu"
On donne une fonction d’affichage d’images (Fig. 50), renormalisées.
def imshow(I, title=None):
I = I.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
I = mean + std * I
I = np.clip(I, 0, 1)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.imshow(I)
plt.savefig('./images.png',dpi=100)
if title is not None:
plt.title(title)
inputs, classes = next(iter(dataloaders['train']))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])

Fig. 50 Quelques exemples d’images.#
Et une fonction d’affichage des prédictions des modèles sur l’ensemble de validation
def predict(model):
was_training = model.training
model.eval()
with torch.no_grad():
# Extraction d'un batch d'évaluation
inputs, labels = next(iter(dataloaders['val']))
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[preds[j]] for j in range(inputs.size()[0])])
model.train(mode=was_training)
Premier entraînement#
Dans ce premier entraînement, on utilise un réseau pré-entraîné, qui sert d’initialisation à un entraînement complet sur la base d’entraînement.
def train1(model, criterion, optimizer, scheduler, num_epochs=25):
# Répertoire temporaire pour les checkpoints
with TemporaryDirectory() as tempdir:
best_model_params_path = os.path.join(tempdir, 'best_params.pt')
torch.save(model.state_dict(), best_model_params_path)
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('*' * 10)
# Le modèle est utilisé en entraînement et en évaluation
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# passe avant
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# rétropropagation et mise à jour des poids en entraînement
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# Mise à jour du learning rate
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Perte: {epoch_loss:.4f} Précision: {epoch_acc:.4f}')
# Sauvegarde du modèle si meilleur
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), best_model_params_path)
# Chargement du meilleur modèle
model.load_state_dict(torch.load(best_model_params_path))
return model
Le réseau utilisé est ResNet34, entraîné sur ImageNet. On ajoute une couche de classification spécifique au problème et on entraîne le tout.
model1 = models.resnet34(weights='IMAGENET1K_V1')
# Nombre de caractéristiques extraites avant le réseau de classification
nb = model1.fc.in_features
# Ajout d'une couche de classification spécifique
model1.fc = nn.Linear(nb, len(class_names))
model1 = model1.to(device)
# Fonction de perte
criterion = nn.CrossEntropyLoss()
# Tous les poids vont être optimisés, y compris ceux du réseau convolutif.
optimizer = optim.SGD(model1.parameters(), lr=0.001, momentum=0.9)
lr_sch = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
model1 = train_model(model1, criterion, optimizer,lr_sch, num_epochs=25)
predict(model1)

Fig. 51 Quelques exemples d’images de validation étiquetées.#
Second entraînement#
Ici, on ne réentraîne pas les poids du réseau convolutif. On laisse donc ce réseau agir comme un extracteur de caractéristiques et on entraîne uniquement les poids de la couche de classification ajouté en bout.
model2 = torchvision.models.resnet34(weights='IMAGENET1K_V1')
# On fige les poids du réseau convolutif
for param in model2.parameters():
param.requires_grad = False
# On ajoute une couche de classification
nb = model2.fc.in_features
model2.fc = nn.Linear(nb, len(class_names))
model2 = model2.to(device)
criterion = nn.CrossEntropyLoss()
# On optimise juste les poids de la couche de classification
optimizer = optim.SGD(model2.fc.parameters(), lr=0.001, momentum=0.9)
lr_sch = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
model2 = train_model(model2, criterion, optimizer,lr_sch, num_epochs=25)
predict(model2)
A vous…#
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 2012. 2012.
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, 2014. URL: http://arxiv.org/abs/1409.1556.
Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, 2013. URL: http://arxiv.org/abs/1312.4400.
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. CoRR, 2014. URL: http://arxiv.org/abs/1409.4842.
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. CoRR, 2015. URL: http://arxiv.org/abs/1512.00567.
François Chollet. Xception: deep learning with depthwise separable convolutions. CoRR, 2016. URL: http://arxiv.org/abs/1610.02357, arXiv:1610.02357.
Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. CoRR, 2016. URL: http://arxiv.org/abs/1602.07261.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, 2015. URL: http://arxiv.org/abs/1512.03385.
Sinno Jialin Pan and Qiang Yang. A survey on transfer learning. IEEE Trans. on Knowl. and Data Eng., 22(10):1345–1359, October 2010. URL: http://dx.doi.org/10.1109/TKDE.2009.191, doi:10.1109/TKDE.2009.191.
Y. Song, T. Wang, P. Cai, S. Mondal, and J. Sahoo. A comprehensive survey of few-shot learning: evolution, applications, challenges, and opportunities. ACM Computing Surveyx, 2023.
Comment utiliser ces réseaux ?#
Il est possible de définir les réseaux classiques en décrivant une à une les couches et leur paramètres, qui sont proposés dans les articles correspondants. On imagine assez bien le travail que cela peut représenter sur ResNet par exemple…
Fort heureusement, il existe d’autres manières d’utiliser ces réseaux.
Utilisation de réseaux pré-entraînés#
Il est possible de charger / sauvegarder des réseaux qui ont été entraînés sur des grandes bases de données et de les utiliser directement. Il est également possible, pendant l’entraînement, de créer des sauvegardes (checkpoints) pour reprendre éventuellement l’entraînement en cours d’itérations. On peut sauvegarder tout le réseau (architecture + optimiseur + poids), ou seulement les poids.
torchvisiondonne accès à de nombreux modèles pré-entrainés :Il est alors facile de charger un tel réseau, par exemple
Transfer learning et fine tuning#
Il est possible d’utiliser les réseaux classiques pré-entrainés pour de nouvelles tâches. L’idée sous-jacente et que les premières couches capturent des caractéristiques bas niveau, et que la sémantique vient avec les couches profondes. Ainsi, dans un problème de classification, où les classes n’ont pas été apprises, on peut supposer qu’en conservant les premières couches on extraira des caractéristiques communes des images, et qu’en changeant les dernières couches (information sémantique et haut niveau et étage de classification), c’est à dire en réapprenant les connexions, on spécifiera le nouveau réseau pour la nouvelle tâche de classification.
Cette approche rentre dans le cadre des méthodes d’apprentissage par transfert (Transfer Learning) [9] et de fine tuning, cas particulier d’adaptation de domaine.
L’apprentissage par transfert comporte généralement deux étapes principales :
Extraction des caractéristiques : dans cette étape,le modèle pré-entraîné est utilisé comme un extracteur de caractéristiques fixes. On supprime les couches finales (MLP, responsable de la classification) et on les remplaçe par de nouvelles couches spécifiques à la tâche adressée (Fig. 46). Les poids du modèle pré-entraîné sont gelés et seuls les poids des couches nouvellement ajoutées sont entraînés sur l’ensemble de données du problème.
Fig. 46 Réentrainement d’un classifieur sur des caractéristiques extraites.#
fine tuning : le fine tuning pousse le processus un peu plus loin en dégelant certaines des couches du modèle pré-entraîné et en leur permettant d’être mises à jour avec le nouvel ensemble de données. Cette étape permet au modèle de s’adapter et d’apprendre des caractéristiques plus spécifiques liées à la nouvelle tâche ou au nouveau domaine.
Plusieurs facteurs influent sur le choix de la méthode à utiliser, parmi lesquels :
la taille des données d’apprentissage du nouveau problème (Fig. 47)
Fig. 47 Stratégies d’apprentissage par transfert.#
la ressemblance du nouveau jeu de données avec celui qui a servi à entraîner le réseau initial (Fig. 48).
Fig. 48 Changement de domaine / tâche.#
Pour un jeu de données similaire de petite taille, on utilise du transfer learning, avec un classifieur utilisé sur les caractéristiques calculées sur les dernières couches du réseau initial. Pour un jeu de données de petite taille et un problème différent, on utilise du transfer learning, avec un classifieur utilisé sur les caractéristiques calculées sur les premières couches du réseau initial. Pour un jeu de données, similaire ou non de grande taille, on utilise le fine tuning
A noter que, si peu de données sont disponibles sur la nouvelle tâche/le nouveau domaine, il est toujours possible :
d’augmenter la taille du jeu de données par des technique de « Data Augmentation » (changement de couleurs des pixels, rotations, cropping, homothéties, translations…) (Fig. 49).
Fig. 49 Augmentation de données : à partir d’un exemple (image de gauche), on construit plusieurs autres exemples par rotation, flip, ajout de bruit, déformation, changement colorimétrique.#
d’utiliser plus généralement des méthodes de Few shot / Zero shot learning [10], dont l’augmentation de données est un exemple.