Soit \(Z = \{ \mathbf x_i , y_i\}, \; i\in[\![1,n]\!] ,\;\mathbf x_i \in {R}^d, y_i \in \{-1,1\}\}\) un ensemble d’apprentissage pour un problème de classification binaire.
SVM linéaire#
Hyperplan séparateur#
Une approche traditionnelle pour introduire les SVM est de partir du concept d’hyperplan séparateur des exemples positifs et négatifs de l’ensemble d’apprentissage. On définit alors la marge comme la distance du plus proche exemple à cet hyperplan, et on espère intuitivement que plus grande sera cette marge, meilleure sera la capacité de généralisation de ce séparateur linéaire.
Un hyperplan de \(\mathbb{R}^d\) est défini par
\(\mathbf w\) étant le vecteur normal à l’hyperplan. La fonction
permet, si elle sépare les données d’apprentissage, de les classifier correctement (Fig. 13).
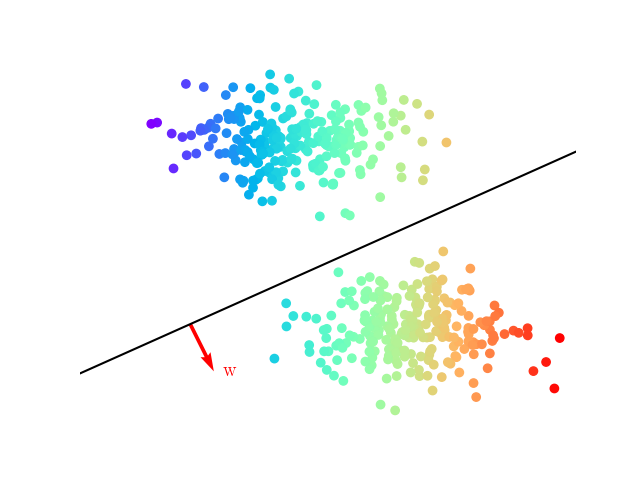
Fig. 13 Hyperplan séparateur et définition de \(\mathbb w\)#
Un tel hyperplan, représenté par (\(\mathbf w,b)\) peut également être exprimé par \((\lambda \mathbf w,\lambda b), \lambda\in\mathbb{R}\). Il est donc nécessaire de définir l’hyperplan canonique comme étant celui éloigné des données d’une distance au moins égale à 1. En fait, on impose qu’un exemple au moins de chaque classe soit à distance égale à 1. On considère alors le couple \((\mathbf w,b)\) tel que :
ou de manière plus compacte
les hyperplans \(\mathbf w^T\mathbf x_i + b =\pm 1\) sont appelés les hyperplans supports.
Une infinité d’hyperplans sépare deux nuages de points linéairement séparables (Fig. 14)
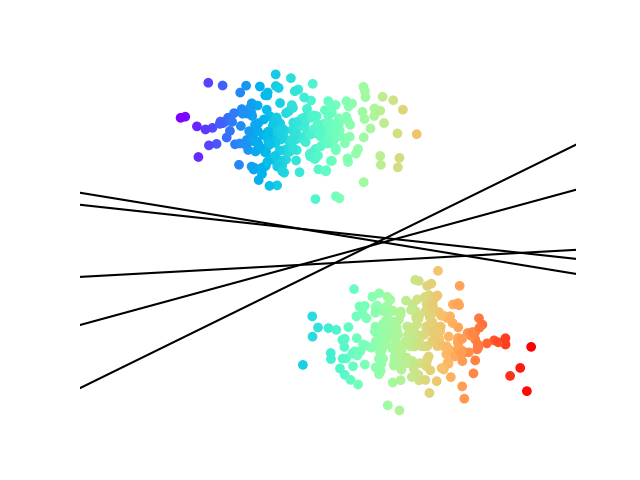
Fig. 14 Hyperplans séparateurs#
On cherche à avoir la marge la plus grande possible, et on suppose qu’au moins un point de donnée appartient aux hyperplans support. Il existe donc \(\mathbf x_1,\mathbf x_2\) tels que \(\mathbf w^T\mathbf x_1 + b =1\) et \(\mathbf w^T\mathbf x_2 + b =-1\). On en déduit
\(\mathbf w\) étant orthogonal aux hyperplans, la marge est la projection orthogonale de \(\mathbf x_1-\mathbf x_2\) sur \(\mathbf w\). Cette projection est définie par la matrice \(P=\frac{\mathbf w\mathbf w^T}{\mathbf w^T\mathbf w}\) et donc le vecteur projection de \(\mathbf x_1-\mathbf x_2\) sur la droite engendrée par \(\mathbf w\) est
L’équation précédente permet d’affirmer que maximiser la marge revient à minimiser \(\|\mathbf w\|\), sous les contraintes de bonne classification (Fig. 15).
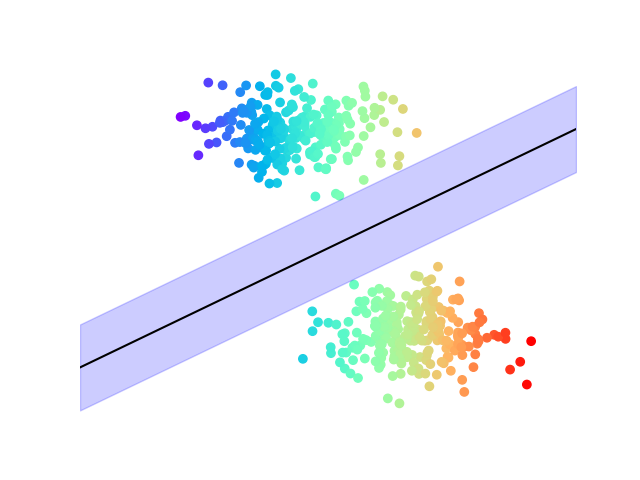
Fig. 15 Maximisation de la marge#
Problème d’optimisation#
Le problème s’écrit alors comme un problème de minimisation sous contraintes :
En introduisant les multiplicateurs de Lagrange, le problème dual s’écrit :
sous
où \(\boldsymbol {\alpha}\) est le vecteur des \(n\) multiplicateurs de Lagrange à déterminer, et \(C\) est une constante. En définissant la matrice \((H)_{ij} = y_iy_j(\mathbf x_i ^T \mathbf x_j)\) et \(\mathbf{1}\) le vecteur de \(\mathbb{R}^n\) dont toutes les composantes sont égales à 1, le problème se réécrit comme un problème de programmation quadratique (QP) :
pour lequel de nombreuses méthodes de résolution ont été développées.
En dérivant l’équation précédente, il est possible de montrer que l’hyperplan optimal (canonique) peut être écrit comme
et \(\mathbf w\) est donc juste une combinaison linéaire des exemples d’apprentissage.
On peut également montrer que
ce qui exprime que lorsque \(y_i(\mathbf w ^T \mathbf x_i + b) > 1\), alors \(\alpha_i = 0\) : seuls les points d’apprentissage les plus proches de l’hyperplan (tels que \(\alpha_i > 0\)) contribuent au calcul de ce dernier, et on les appelle les vecteurs de support.
En supposant avoir résolu le problème QP, et donc en disposant du \(\boldsymbol {\alpha}\) qui permet de calculer le vecteur \(\mathbf w\) optimal, il reste à déterminer le biais \(b\). Pour cela, en prenant un exemple positif \(\mathbf x^+\) et un exemple négatif \(\mathbf x^-\) quelconques, pour lesquels
on a
L’hyperplan ainsi défini a besoin de très peu de vecteurs de support (méthode éparse) (Fig. 16).
from sklearn.svm import LinearSVC
X,y=...
svm_clf=LinearSVC(random_state=0,tol=1e-05)
svm_clf.fit(X, y);
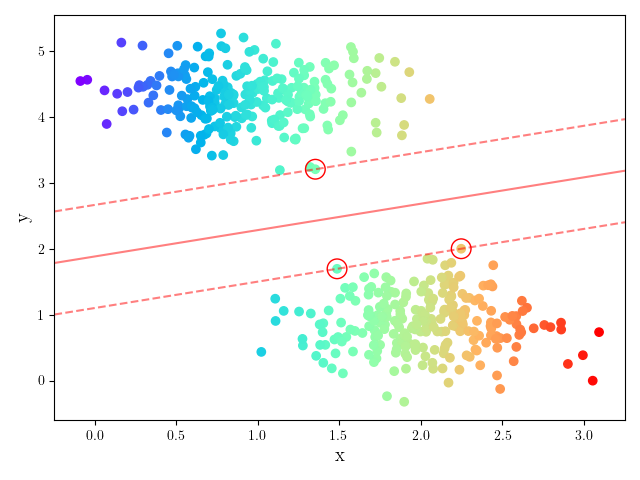
Fig. 16 Les vecteurs de support sont entourés.#
Données non linéairement séparables#
Il reste à préciser le rôle de la contrainte \({0} \le {\boldsymbol \alpha} \le C\mathbf{1}\). Lorsque \(C\rightarrow\infty\), l’hyperplan optimal est celui qui sépare totalement les données d’apprentissage (si tant est qu’il existe). Pour des valeurs de \(C\) « raisonnables », des erreurs de classification peuvent être acceptées par le classifieur (soft margin). Pour cela on introduit des variables d’écart \(\xi_i\) :
Les vecteurs de support vérifient l’égalité, et les anciennes contraintes peuvent être violées de deux manières :
\((\mathbf x_i,y_i)\) est à distance inférieure à la marge, mais du bon côté de l’hyperplan
\((\mathbf x_i,y_i)\) est du mauvais côté de l’hyperplan
L’objectif est alors de minimiser la moyenne des erreurs de classification \(\displaystyle\sum_{i=1}^n \mathbf{1}_{\xi_i>0}\). Ce problème étant NP-complet (fonction non continue et dérivable), on lui préfère le problème suivant
\(C\) représente alors un compromis entre la marge possible entre les exemples et le nombre d’erreurs admissibles. Nous illustrons dans la suite deux situations influencées par \(C\) :
La Fig. 17 présente une première illustration du rôle de \(C\) : dans le cas de données linéairement séparables, un \(C\) faible autorisera des vecteurs à rentrer dans la marge (vert). Plus \(C\) devient grand, plus le nombre de vecteurs support diminue, pour ne laisser aucun vecteur à distance inférieure à la marge de l’hyperplan optimal
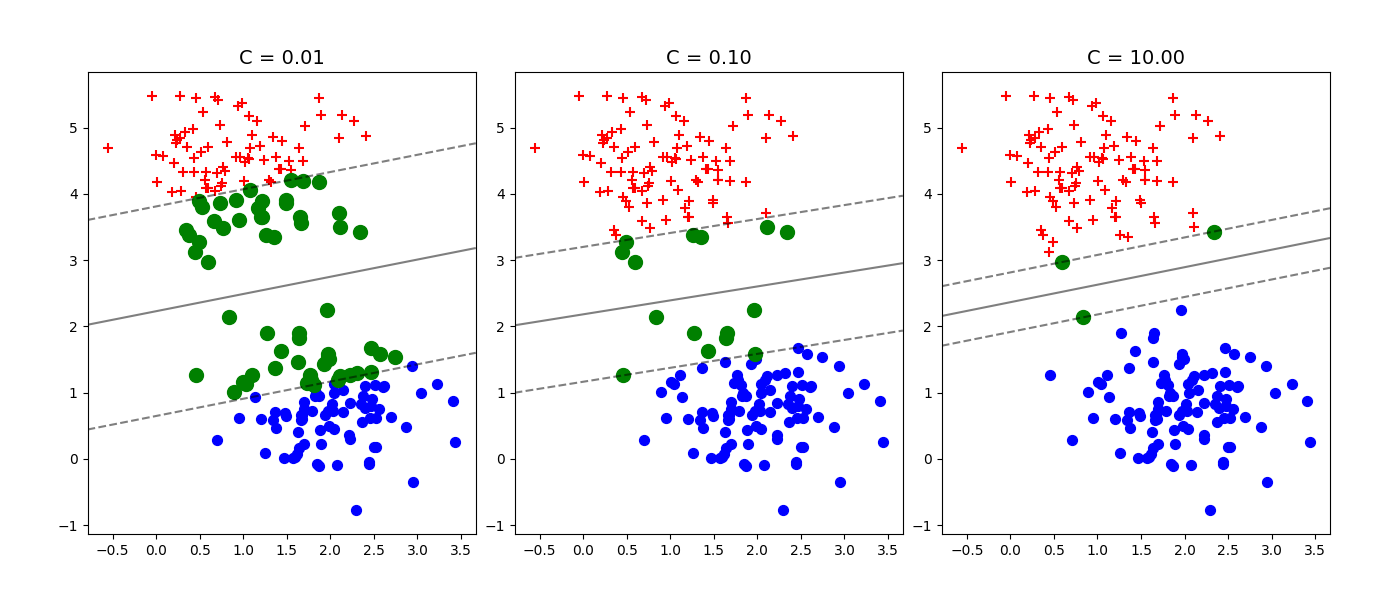
Fig. 17 Données linéairement séparables#
from IPython.display import Video
Video("videos/influencec.mp4",embed =True,width=500)
from sklearn.svm import SVC
X,y=...
svm_clf=SVC(kernel="linear", C=1E10)
svm_clf.fit(X, y);
La Fig. 18 présente un ensemble de données non linéairement séparables. La valeur de \(C\) contrôle le nombre d’erreurs de classification dans le résultat final.
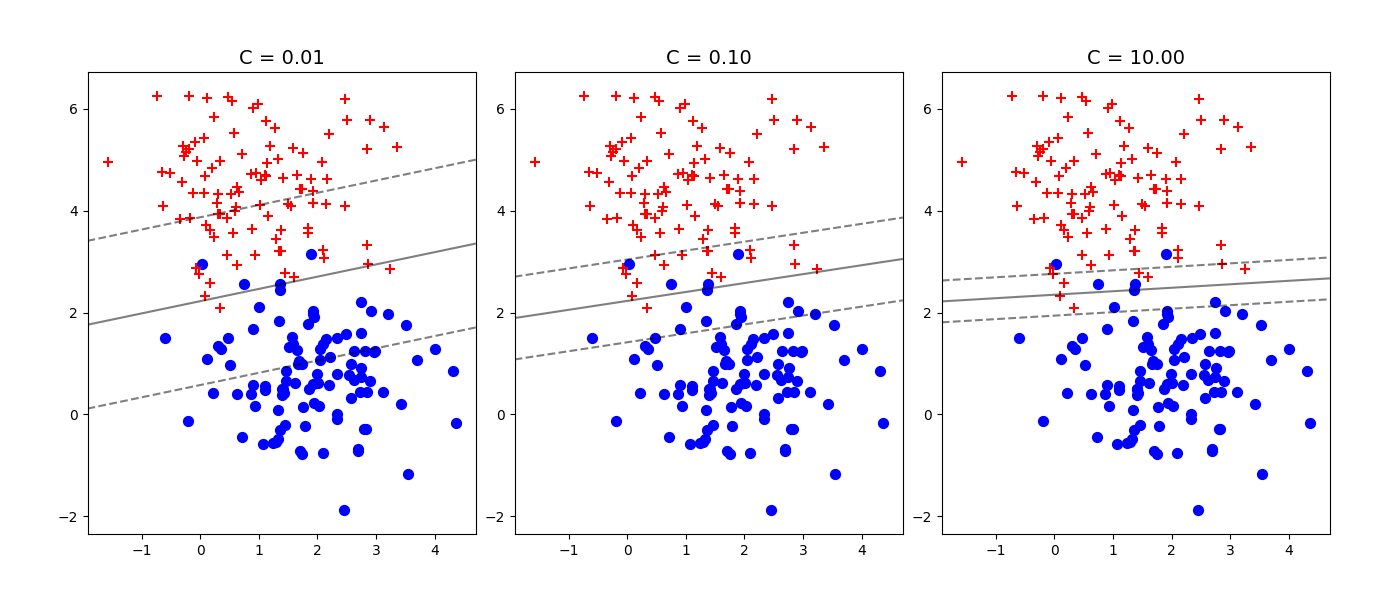
Fig. 18 Données non linéairement séparables#
Cas multiclasses#
Deux stratégies sont possibles dans le cas multiclasse :
Transformer le problème à \(k\) classes en \(k\) classifieurs binaires, la classe de l’exemple est donnée par le classifieur qui répond le mieux
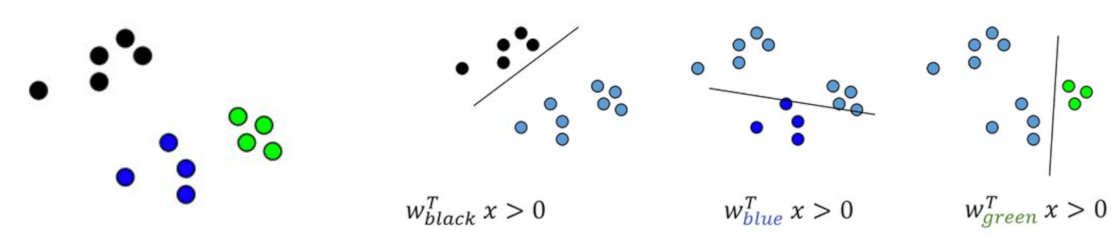
Transformer le problème en \(\frac{k(k-1)}{2}\) classifieurs binaires, chaque classe étant comparée aux autres. La classe de l’exemple est donnée par le vote majoritaire ou par un graphe acyclique de décision

SVM non linéaire#
Pour utiliser les SVM dans un contexte non linéaire, on profite de l”astuce du noyau puisque le modèle s’écrit avec un produit scalaire canonique.
Utilisation en régression#
Il est également possible, en changeant les fonctions de perte, d’utiliser les SVM en régression non paramétrique (SVR : Support Vector Regression) , i.e. approcher une fonction de \(\mathbb{R}^d\) dans \(\mathbb{R}^p\) par les mêmes mécanismes d’optimisation.
Pour illustrer les SVR, on génère des données aléatoires 2D à tendance linéaire et on utilise LinearSVR pour effectuer une régression linéaire.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
m = 50
X = 2 * np.random.rand(m, 1)
y = (4 + 3 * X + np.random.randn(m, 1)).ravel()
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.set_xlabel(r"$x$", fontsize=14)
ax.set_ylabel(r"$y$", fontsize=14)
ax.plot(X, y,"bo");
plt.tight_layout()
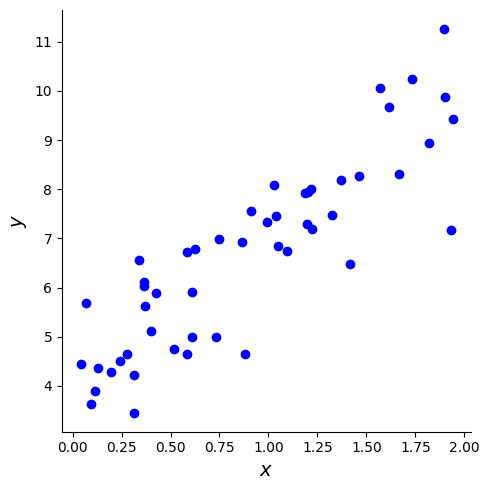
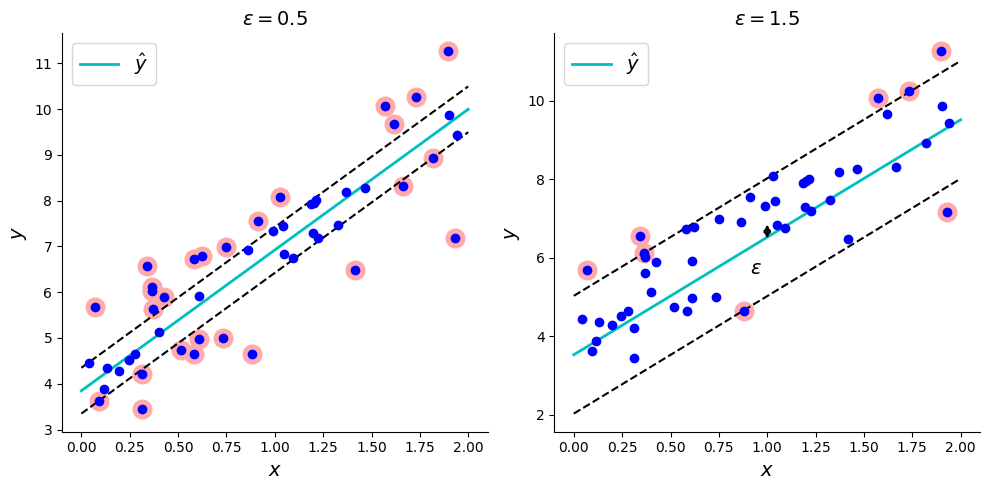
Un SVR linéaire est principalement défini par un paramètre \(\epsilon\), qui spécifie la largeur du tube dans lequel aucune pénalité n’est associée.
from sklearn.svm import LinearSVR
svm_reg1 = LinearSVR(epsilon=0.5, random_state=42)
svm_reg2 = LinearSVR(epsilon=1.5, random_state=42)
svm_reg1.fit(X, y)
svm_reg2.fit(X, y)
def find_support_vectors(svm_reg, X, y):
y_pred = svm_reg.predict(X)
off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)
return np.argwhere(off_margin)
svm_reg1.support_ = find_support_vectors(svm_reg1, X, y)
svm_reg2.support_ = find_support_vectors(svm_reg2, X, y)
eps_x1 = 1
eps_y_pred = svm_reg1.predict([[eps_x1]])
On affiche alors les régresseurs linéaires
def plot_svm_regression(svm_reg, ax,X, y, axes):
x1s = np.linspace(axes[0], axes[1], 100).reshape(100, 1)
y_pred = svm_reg.predict(x1s)
ax.plot(x1s, y_pred, "c-", linewidth=2, label=r"$\hat{y}$")
ax.plot(x1s, y_pred + svm_reg.epsilon, "k--")
ax.plot(x1s, y_pred - svm_reg.epsilon, "k--")
ax.scatter(X[svm_reg.support_], y[svm_reg.support_], s=180, facecolors='#FFAAAA')
ax.plot(X, y, "bo")
ax.set_xlabel(r"$x$", fontsize=14)
ax.set_ylabel(r"$y$", fontsize=14)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.legend(loc="upper left", fontsize=14)
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
plot_svm_regression(svm_reg1, ax[0],X, y, [0, 2, 3, 11])
ax[0].set_title(r"$\epsilon = {}$".format(svm_reg1.epsilon), fontsize=14)
plt.annotate(
'', xy=(eps_x1, eps_y_pred), xycoords='data',
xytext=(eps_x1, eps_y_pred - svm_reg1.epsilon),
textcoords='data', arrowprops={'arrowstyle': '<->', 'linewidth': 1.5}
)
plt.text(0.91, 5.6, r"$\epsilon$", fontsize=14)
plot_svm_regression(svm_reg2,ax[1], X, y, [0, 2, 3, 11])
ax[1].set_title(r"$\epsilon = {}$".format(svm_reg2.epsilon), fontsize=14)
plt.tight_layout()
from IPython.display import Video
Video("videos/svr_regression_lin.mp4",embed =True,width=500)
Thomas M. Cover. Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. Electronic Computers, IEEE Transactions on, EC-14(3):326–334, 1965. URL: http://hebb.mit.edu/courses/9.641/2002/readings/Cover65.pdf.
V. N. Vapnik and A. Ya. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability and its Applications, 16(2):264–280, 1971.
Vladimir Vapnik. Principles of risk minimization for learning theory. In NIPS, 831–838. Morgan Kaufmann, 1991.