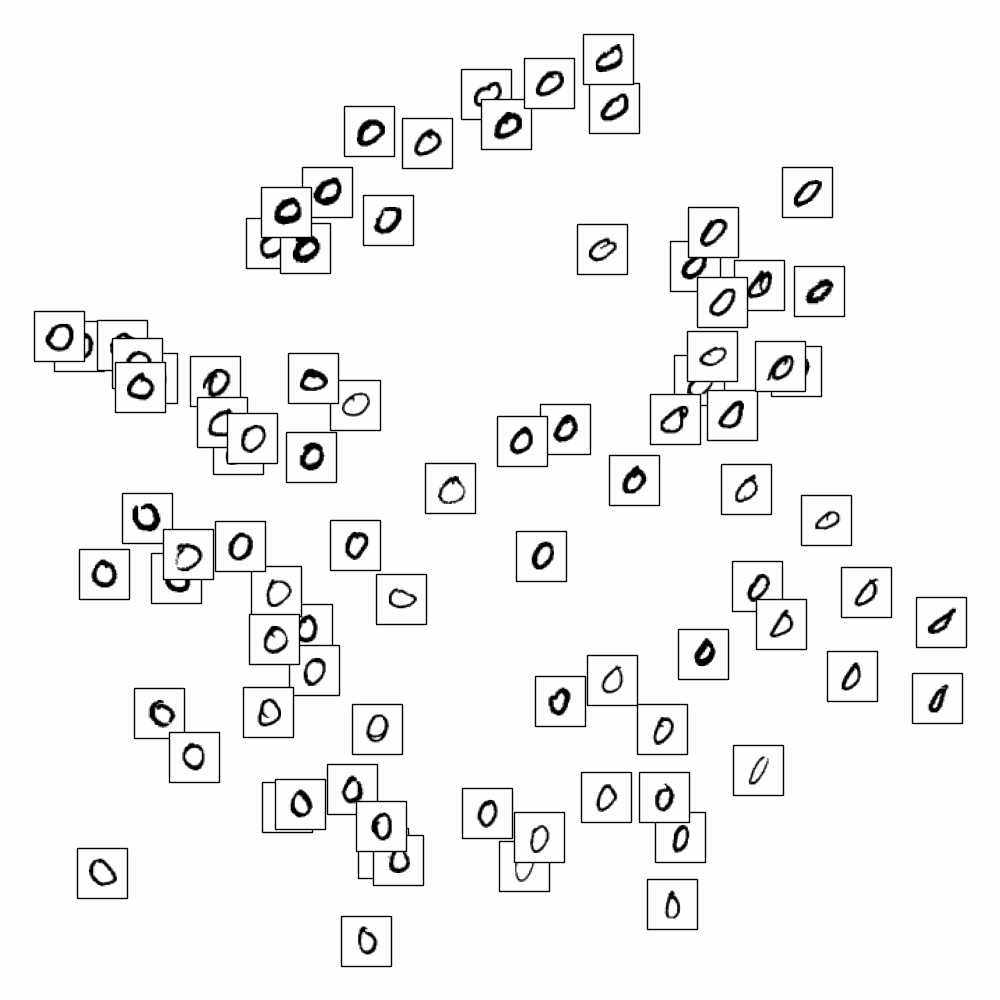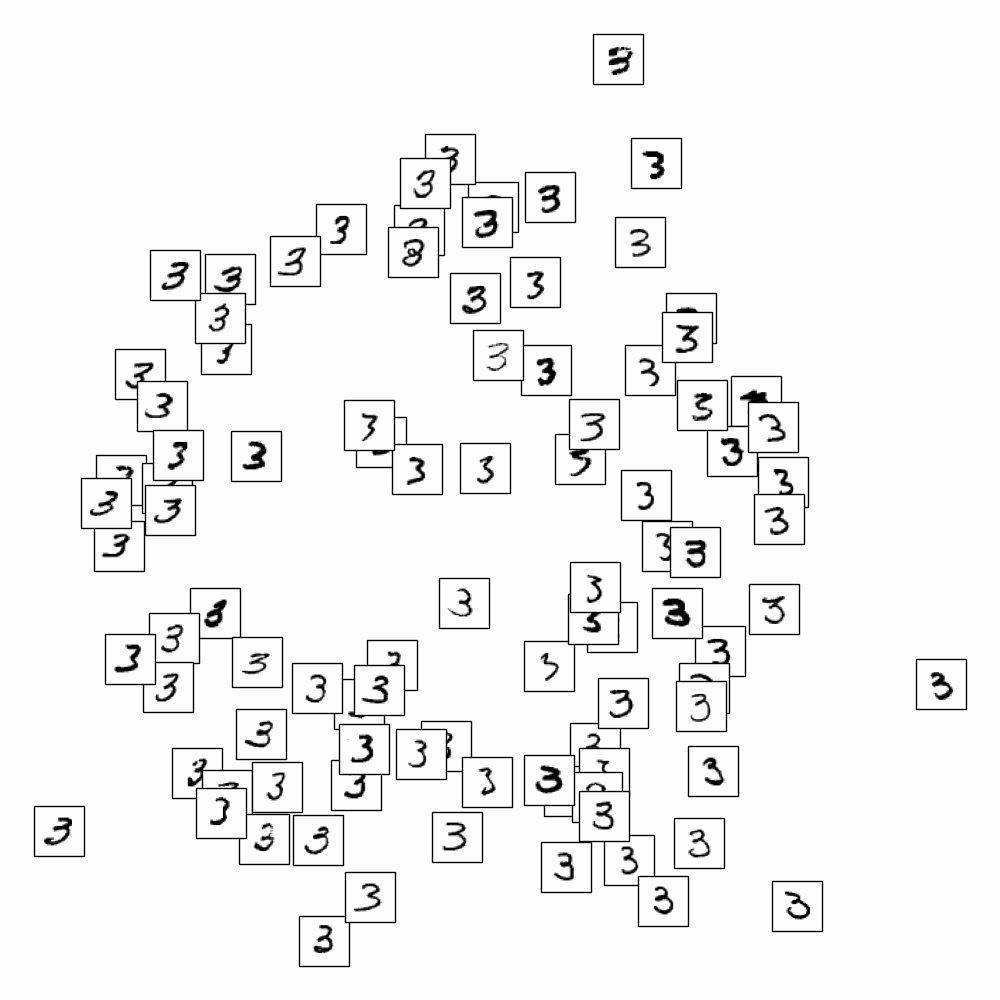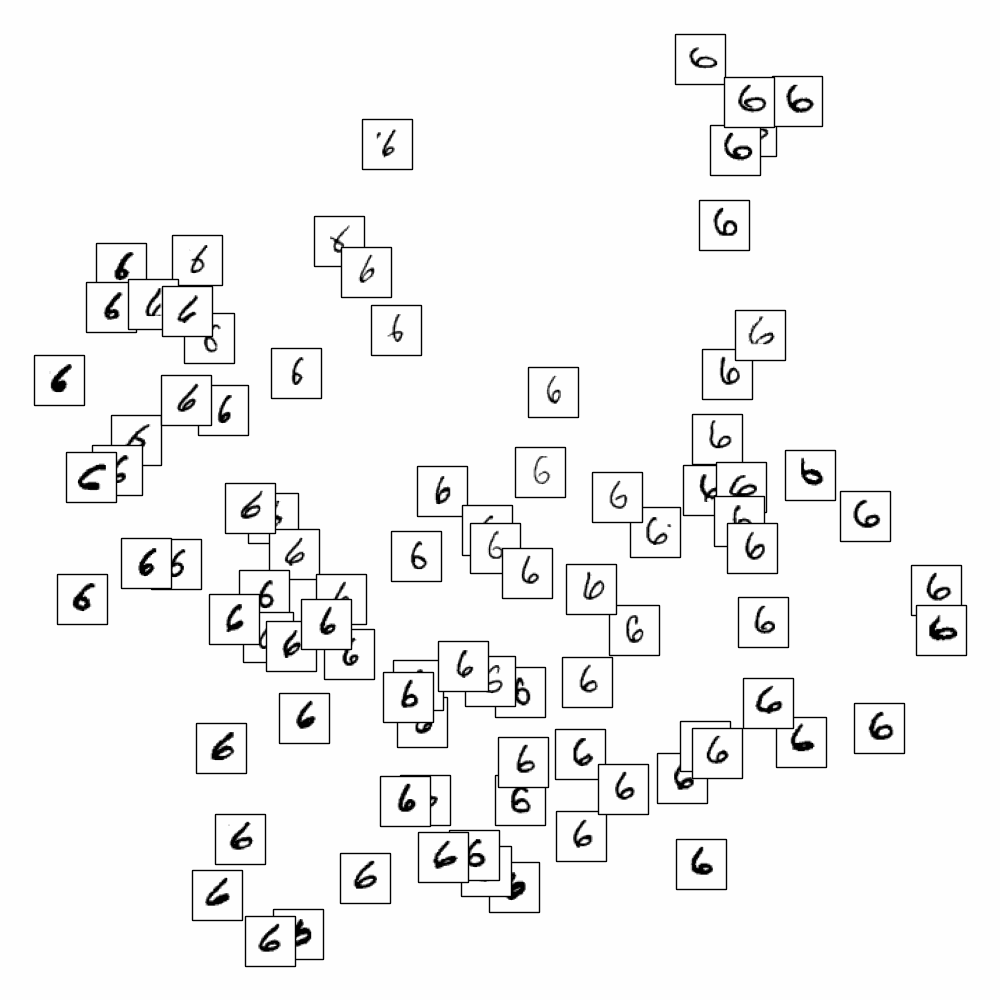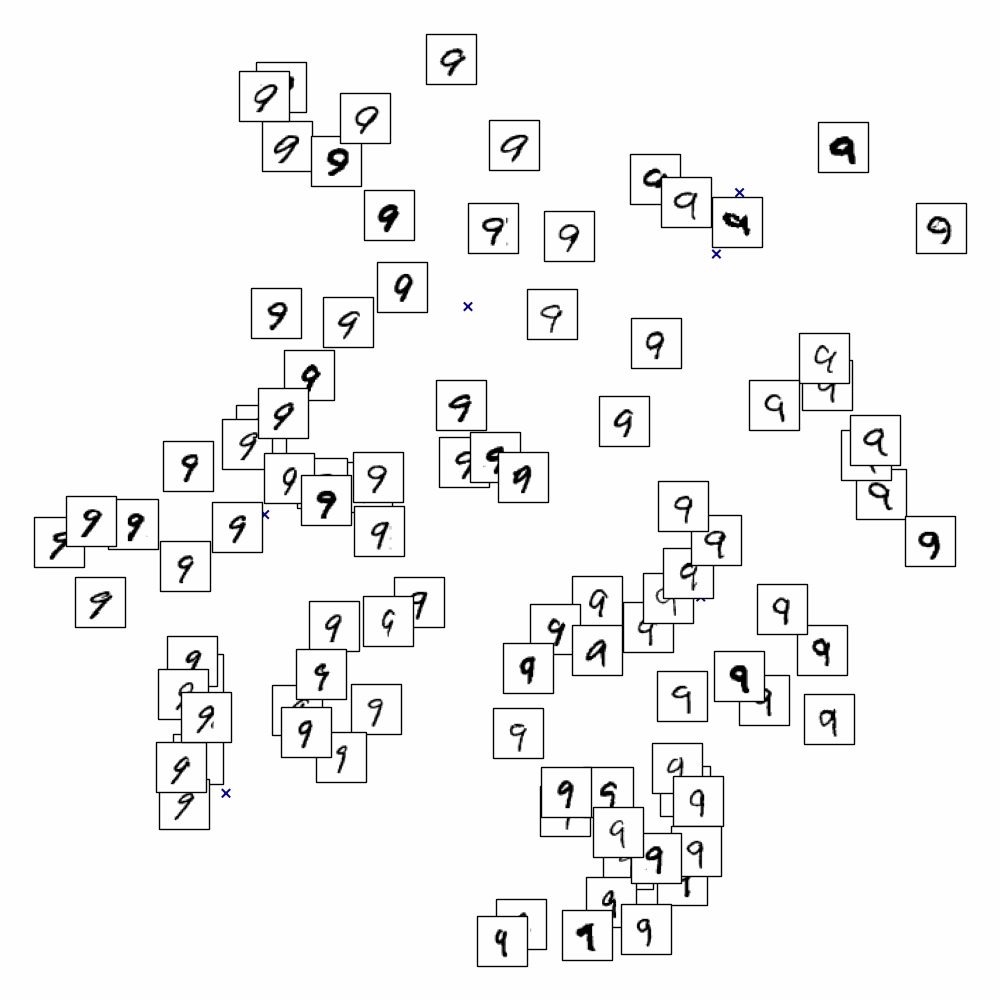Local Linear Embedding#
L’algorithme de plongement localement linéaire (Local Linear Embedding, LLE) est similaire dans l’esprit à ISOMAP, mais agit d’un point de vue local puisqu’il tente de préserver les informations locales sur la variété riemannienne plutôt que d’estimer les distances géodésiques.
Algorithme#
Recherche des plus proches voisins : pour \(K_i<<d\), on note \(N_i^{K_i}\) le voisinage de \(\mathbf x_i\) composé de ses \(K_i\) plus proches voisins, calculés en utilisant la distance euclidienne. \(K_i\) est indicé par \(i\) car il peut être différent pour chaque point de donnée.
Reconstruction par moindres carrés contraints : en faisant l’approximation d’ordre 1 que, localement, une variété est linéaire, on reconstruit \(x_i\) comme combinaison linéaire de ses \(K_i\) plus proches voisins :
On impose aux \(w_{ij}\) de sommer à 1 pour être invariant en translation, et si la somme est effectuée pour tous les points, alors \(w_{ij}=0\) si \(\mathbf x_j\notin N_i^{K_i}\). On note \(W=\left (w_{ij}\right )\) et on cherche les pondérations \(\hat{w}_{ij}\) résolvant le problème d’optimisation contraint :
Pour \(i\in[\![1,n]\!]\), on note
où \(\mathbf w_i=(w_{i1}\cdots w_{in})^T\in\mathbb{R}^n\) et \(G_i\) est la matrice de Gram associée à \(\mathbf x_i\), de coefficients
La relaxation lagrangienne du problème d’optimisation amène à minimiser
où \(\lambda\) est le multiplicateur de Lagrange associé à la contrainte de somme unité, et \(1_n\) est le vecteur de \(\mathbb{R}^n\) composé uniquement de 1. L’annulation de la dérivée partielle par rapport à \(\mathbf w_i\) donne \(\hat{\mathbf w}_i=\frac{\lambda}{2}G_i^{-1}1_n\). En multipliant à gauche par \(1_n^T\), on obtient finalement
On forme alors \(\hat{W}\) la matrice dont les colonnes sont les \(\hat{\mathbf w}_i\).
Plongement spectral : on recherche enfin la matrice \(Y\) de taille \(t\times n\) donnant les vecteurs \(\mathbf y_i\) en résolvant le problème d’optimisation
Les contraintes déterminent le positionnement (translation, rotation, échelle) des coordonnées \(\mathbf y_i\). \
La fonction objectif peut être réécrite
avec \(M=(I-\hat{W})^T(I-\hat{W})\). Cette fonction a un minimum global unique donné par les vecteurs propres correspondant aux t+1 plus petites valeurs propres de \(M\), associées aux vecteurs propres \(\mathbf{v}_n\cdots \mathbf{v}_{n-t}\). La plus petite d’entre elles est 0, correspondant à \(\mathbf{v}_n=\frac{1}{\sqrt{n}}1_n\). Puisque la somme des coefficients de chacun des autres vecteurs propres, qui sont orthogonaux à \(\mathbf{v}_n\), est zéro, ignorer \(v_n\) et sa valeur propre associée contraindra les coordonnées \(\mathbf y_i\) d’être de somme nulle. La solution optimale est donc
On applique LLE sur les données MNIST et on cherche à représenter les images (vecteurs de \(\mathbb{R}^{784}\)) dans \(\mathbb{R}^{2}\)
from IPython.display import Video
Video("videos/lle.mp4",embed =True,width=800)
Contrairement à ISOMAP, LLE gère assez bien les variétés non convexes, puisque l’algorithme préserve les propriétés géométriques locales, plutôt que globales. En, revanche, les variétés à trou sont également difficiles à traiter par cet algorithme.
Exemple d’application#
On applique LLE sur les données MNIST et on cherche à représenter les images (vecteurs de \(\mathbb{R}^{784}\)) dans \(\mathbb{R}^{2}\)

En affichant uniquement les chiffres de 0 à 9, on s’aperçoit que LLE sépare également les styles pour un même chiffre.