try:
import pandas
except ModuleNotFoundError:
!pip3 install --quiet pandas
import numpy, matplotlib,pandas
Quelques méthodes de classification#
Introduction#
La classification automatique a pour but d’obtenir une représentation simplifiée des données initiales. Elle consiste à organiser un ensemble de données en classes homogènes ou classes naturelles.
Une définition formelle de la classification, qui puisse servir de base à un processus automatisé, amène à se poser les questions suivantes :
Comment les objets à classer sont-ils définis ?
Comment définir la notion de ressemblance entre objets ?
Qu’est-ce qu’une classe ?
Comment sont structurées les classes ?
Comment juger une classification par rapport à une autre ?
Pour effectuer cette classification, deux démarches sont généralement utilisées :
on regroupe en classes les objets qui partagent certaines caractéristiques.
on regroupe en classes les objets qui possèdent des caractéristiques proches. C’est cette approche qui est étudiée ici
Structures de classification#
Partition#
Definition 40 (Partition)
\(\Omega\) étant un ensemble fini, un ensemble \(P =(P_1 ,P_2 ,\cdots P_g )\) de parties non vides de \(\Omega\) est une partition si :
\((\forall k\neq l) P_k \cap P_l=\emptyset\)
\(\displaystyle\cup_{i=1}^gP_i=\Omega\)
Dans un ensemble \(\Omega\) partitionné en \(g\) classes, chaque élément de l’ensemble appartient à une classe et une seule. Une manière pratique de décrire cette partition \(P\) consiste à lui associer la matrice de classification \({\bf C}=(c_{ij}), i\in [\![1,n]\!], j\in [\![1,g]\!]\), avec \(c_{ij}=1\) si l’individu \(i\) appartient à \(P_j\), et \(c_{ij}=0\) sinon. Dans le cas où l’on accepte qu’un individu appartienne à plusieurs classes (avec des degrés d’appartenance), on autorise \(c_{ij}\) à couvrir l’intervalle [0,1] et on parle alors de classification floue.
Hiérarchie indicée#
Definition 41 (Hiérarchie)
\(\Omega\) étant un ensemble fini, un ensemble \(H\) de parties non vides de \(\Omega\) est une hiérarchie sur \(\Omega\) si :
\(\Omega \in H\)
\((\forall x\in \Omega) \{x\}\in H\)
\((\forall h,h'\in H) h\cap h'=\emptyset\) ou \(h\subset h'\) ou \(h'\subset h\)
Une hiérarchie est souvent représentée par l’intermédiaire d’un indice, fonction \(i\) de \(H\) dans \(\mathbb{R}^+\), strictement croissante vis à vis de l’inclusion et de noyau l’ensemble des singletons de \(\Omega\).
Partition et hiérarchie#
Si \(P =(P_1 \cdots,P_g)\) est une partition de \(\Omega\), l’ensemble \(H\) formé des classes \(P_k\) de \(P\), des singletons de \(\Omega\) et de l’ensemble \(\Omega\) lui-même forme une hiérarchie. Remarquons qu’inversement, il est possible d’associer à chaque niveau d’une hiérarchie indicée une partition. Une hiérarchie indicée correspond donc à un ensemble de partitions emboîtées.
Objectifs de la classification#
Difficultés de caractériser les objectifs#
L’objectif de la classification automatique est l’organisation en classes homogènes des éléments d’un ensemble \(\Omega\). Pour définir cette notion de classes homogènes, on utilise le plus souvent une mesure de similarité (ou de dissimilarité) sur \(\Omega\). Par exemple, on peut imposer à un couple quelconque d’individus d’une même classe d’être plus « proches » que n’importe quel couple formé par un individu de la classe et un individu d’une autre classe. En pratique, cet objectif est inutilisable, et plusieurs démarches sont alors utilisées pour remplacer cet objectif trop difficile à atteindre.
Démarche numérique#
Partition#
On remplace cette condition trop exigeante par une fonction numérique (critère) qui mesure la qualité d’homogénéité d’une partition. Le problème peut paraître alors très simple. En effet, par exemple, dans le cas de la recherche d’une partition, il suffit de chercher parmi l’ensemble fini de toutes les partitions celle qui optimise le critère numérique. Malheureusement, le nombre de ces partitions étant très grand, leur énumération est impossible dans un temps raisonnable. Le nombre de partitions en \(g\) classes d’un ensemble à \(n\) éléments, que l’on note \(S_n^g\) est le nombre de Stirling de deuxième espèce. En posant \(S_0^0=1\) et pour tout \(n>0\), \(S_n^0=S_0^n=0\), il peut être calculé par récurrence grâce à la relation \(S_n^g=S_{n-1}^{g-1}+gS_{n-1}^g\). On peut montrer que
et donc \(S_n^g\sim \frac{g^n}{g!}\) lorsque \(n\rightarrow\infty\). En pratique, sur un ordinateur calculant \(10^6\) partitions par seconde, il faut 126 000 ans pour calculer l’ensemble des partitions d’un ensemble à \(n=25\) éléments.
On utilise alors des heuristiques qui donnent, non pas la meilleure solution, mais une « bonne solution », proche de la solution optimale. On parle alors d’optimisation locale. Lorsqu’il existe une structure d’ordre sur l’ensemble \(\Omega\) et que celle-ci doit être respectée par la partition, il existe un algorithme de programmation dynamique (algorithme de Fisher), qui fournit la solution optimale.
Hiérarchie#
Dans le cas d’une hiérarchie, on cherche à obtenir des classes d’autant plus homogènes qu’elles sont situées dans le bas de la hiérarchie. La définition d’un critère est moins facile. Nous verrons qu’il est possible de le faire en utilisant la notion d’ultramétrique (ultramétrique optimale).
Démarche algorithmique#
Il s’agit cette fois de définir directement un algorithme qui construit des classes homogènes en tenant compte de la mesure de similarité. Il est relativement facile de proposer de tels algorithmes, le problème est de pouvoir vérifier que les résultats fournis sont intéressants et répondent au problème posé. En réalité, cette démarche rejoint assez souvent la précédente.
Mesure de dissimilarité et distance#
Les algorithmes de classification dépendent d’une métrique qui définit implicitement la forme des classes qui seront calculées. Si la distance euclidienne suppose une isotropie dans les axes (et donc une représentation sphérique des classes), d’autres distances ou indices de dissimilarité peuvent être utilisés.
Indice de dissimilarité#
On se place dans \(\mathbb R^d\), et on considère \(n\) individus à classer \({\bf x_1}\ldots {\bf x_n}\).
Definition 42 (Dissimilarité - ultramétrique)
Une mesure de dissimilarité \(\delta\) est une fonction de
\( \delta: \begin{array}{ccc} \mathbb{R}^d\times\mathbb{R}^d &\rightarrow &\mathbb{R}^+\\ (\mathbf x_i,\mathbf x_j)&\mapsto & \delta_{ij} = \delta(\mathbf x_i,\mathbf x_j) \end{array} \)
vérifiant :
\((\forall i,j\in[\![1, n]\!])\ \delta_{ij}=\delta_{ji}\)
\((\forall i\in[\![1, n]\!])\ \delta_{ii}= 0\)
Si l’inégalité triangulaire \(\delta_{ij}\leq \delta_{ik}+\delta_{kj}\) est de plus vérifiée pour tout \(i,j,k\), alors \(\delta\) est une distance.
Si enfin l’inégalité ultramétrique \(\delta_{ij}\leq max(\delta_{ik}+\delta_{jk})\) est vérifiée pour tout \(i,j,k\), \(\delta\) est une ultramétrique.
A partir des mesures de dissimilarité, on déduit des mesures de similarité \(s_{ij}\) le passage de l’une à l’autre se faisant par exemple par \(\delta_{ij} = s_{max}-s_{ij}\).
Cas de variables qualitatives#
On suppose que les \(d\) composantes des \({\bf x_i}\) sont qualitatives, et on se limite ici au cas de variables bimodales. Étant donnés \({\bf x_i}=\begin{pmatrix} x_i^1\ldots x_i^d\end{pmatrix}\) et \({\bf x_j}\), on note :
\(a_{ij}\) le nombre de co-occurences entre les individus \(i\) et \(j\)
\(b_{ij}\) le nombre de co-absences entre les individus \(i\) et \(j\)
\(c_{ij}\) le nombre d’attributs présents chez \(i\) et absents chez \(j\)
\(d_{ij}\) le nombre d’attributs absents chez \(i\) et présents chez \(j\)
les mesures suivantes sont des exemples de dissimilarité :
\(\delta_{ij} = \sqrt{b_{ij}+c_{ij}}\) [distance « euclidienne » binaire]
\(\delta_{ij} = \frac{(b_{ij}-c_{ij})^2}{(a_{ij}+b_{ij}+c_{ij}+d_{ij})^2}\) [différence binaire de taille]
\(\delta_{ij} = \frac{(b_{ij}c_{ij})}{(a_{ij}+b_{ij}+c_{ij}+d_{ij})^2}\) [différence binaire de motif]
\(\delta_{ij} = \frac{(a_{ij}+b_{ij}+c_{ij}+d_{ij})(b_{ij}+c_{ij})-(b_{ij}-c_{ij})^2}{(a_{ij}+b_{ij}+c_{ij}+d_{ij})^2}\) [différence binaire de forme]
\(\delta_{ij} = \frac{(b_{ij}+c_{ij})}{4(a_{ij}+b_{ij}+c_{ij}+d_{ij})}\) [dissimilarité binaire de variance]
\(\delta_{ij} = \frac{(b_{ij}+c_{ij})}{2a_{ij}+b_{ij}+c_{ij}}\) [dissimilarité binaire de Lance et Williams]
Cas de variables quantitatives#
Dans le cas de variables quantitatives, les normes \(L_p\) :
\(\|{\bf x_i}\|_p=\left (\displaystyle\sum_{j=1}^d|x_i^j|^p\right ) ^\frac{1}{p}\)
sont classiquement utilisées, et par exemple
\(p=1\) : \(\|{\bf x_i}-{\bf x_j}\|_1=\displaystyle\sum_{k=1}^d|x_i^k-x_j^k|\) est la norme \(L_1\) (ou city block).
\(p=2\) : \(\|{\bf x_i}-{\bf x_j}\|_2=\sqrt{\displaystyle\sum_{k=1}^d(x_i^k-x_j^k)^2}\) est la norme \(L_2\) (ou norme euclidienne).
« \(p=\infty\) » : \(\|{\bf x_i}-{\bf x_j}\|_\infty = \displaystyle\max_{1\leq k\leq d}\{|x_i^k-x_j^k|\}\) est la norme du max (ou norme de Tchebychev)
Si les variables ne sont pas normalisées, on peut utiliser la distance de Mahalanobis
\(\delta_{ij} = \displaystyle\sum_{k=1}^d\displaystyle\sum_{l=1}^dw_{kl}(x_i^k-x_j^k)(x_i^l-x_j^l)\)
où la matrice des \(w_{kl}\) est l’inverse de la matrice de covariance empirique. Cette distance élimine également les corrélations entre variables.
Enfin, on peut utiliser une métrique issue du coefficient de corrélation, dite distance de Pearson : \(\delta_{ij} =\sqrt{1-r^2_{ij}}\), avec
\(r^2_{ij} = \frac{\left (\displaystyle\sum_{k=1}^d (x_i^k-\bar{x_i})(x_j^k-\bar{x_j})\right )^2}{\displaystyle\sum_{k=1}^d(x_i^k-\bar{x_i})^2\displaystyle\sum_{k=1}^d(x_j^k-\bar{x_j})^2}\)
Variables de comptage#
Dans le cas particulier de variables de comptage (\(x_i^k\) effectif de la classe \(k\) pour l’individu \(i\)), une mesure naturelle de dissimilarité entre \({\bf x_i}\) et \({\bf x_j}\) est le \(\chi^2\) du tableau de contingence 2\(\times d\) associé.
Quelle mesure choisir ?#
Une réflexion sur le type de dissimilarité à choisir est nécessaire. Il est en particulier intéressant de répondre aux questions suivantes:
de quelles variables initiales (qualitatives et/ou quantitatives) doit dépendre la dissimilarité?
est-il souhaitable (et possible) d’obtenir des variables pertinentes supplémentaires? Si oui par mesure ? par analyse linéaire (ACP,…) ou non linéaire (manifold learning) ?
quelles doivent être les importances relatives des diverses variables retenues dans la constitution de la dissimilarité ?
Classification ascendante hiérarchique#
L’objectif est de construire une hiérarchie indicée d’un ensemble \(\Omega\) sur lequel on connaît une mesure de dissimilarité \(\delta\) telle que les points les plus proches soient regroupés dans les classes de plus petit indice. La hiérarchie est alors construite en appliquant itérativement ce principe, et l’arbre obtenu sur l’ensemble des itérations est appelé un dendrogramme.
Il existe essentiellement deux approches :
la classification descendante : on divise \(\Omega\) en classes, puis on recommence sur chacune de ces classes itérativement jusqu’à ce que les classes soient réduites à des singletons.
la classification ascendante : cette fois on part de la partition de \(\Omega\) où chaque classe est un singleton. On procède alors par fusions successives des classes jusqu’à obtenir une seule classe, c’est-à -dire l’ensemble \(\Omega\) lui-même. Nous insistons sur ce type de classification dans la suite.
Algorithme#
Construction de la hiérarchie#
\(\Omega\) étant l’ensemble à classifier et \(\delta\) une mesure de dissimilarité sur cet ensemble, on définit à partir de \(\delta\) une distance \(D\) entre les parties de \(\Omega\). Cette distance est en réalité une mesure de dissimilarité qui ne vérifie pas nécessairement toutes les propriétés d’une distance sur l’ensemble des parties de \(\Omega\). En général, \(D\) est appelé critère d’agrégation. L’algorithme est alors le suivant :
Algorithm 7 (Algorithme de clustering hiérarchique ascendant)
Entrée : Les éléments de \(\Omega\)
Sortie : Une hiérarchie
Initialisation : partition des singletons
Calcul des distances entre classes.
Tant que le nombre de classes est \(>\)1
Regroupement des 2 classes les plus proches au sens de \(D\)
Calcul des distances entre la nouvelle classe et les anciennes classes non regroupées.
Il est facile de montrer que l’ensemble des classes définies au cours de cet algorithme forme une hiérarchie.
Construction de l’indice#
Après avoir défini une hiérarchie, il est nécessaire de lui associer un indice. Pour les classes du bas de la hiérarchie, c’est-à-dire les singletons, cet indice est nécessairement la valeur 0. Pour les autres classes, cet indice est généralement défini en associant à chacune des classes construites au cours de l’algorithme la distance \(D\) qui séparait les deux classes fusionnées pour former cette nouvelle classe. Pour que cette définition conduise bien à un indice, il est nécessaire que les indices obtenus soient strictement croissants avec le niveau de la hiérarchie. Plusieurs difficultés peuvent alors apparaître :
pour certains critères d’agrégation, l’indice ainsi défini n’est pas nécessairement croissant. On parle alors d’inversion. Par exemple, si les données sont formées par trois points du plan situés au sommet d’un triangle équilatéral de côté 1 et si on prend comme distance \(D\) entre classes la distance entre les centres de gravité, on obtient une inversion.
lorsqu’il y a égalité de l’indice pour plusieurs niveaux emboîtés, il suffit de filtrer la hiérarchie, c’est-à-dire conserver une seule classe qui regroupe toutes les classes emboîtées ayant le même indice.
Critères d’agrégation#
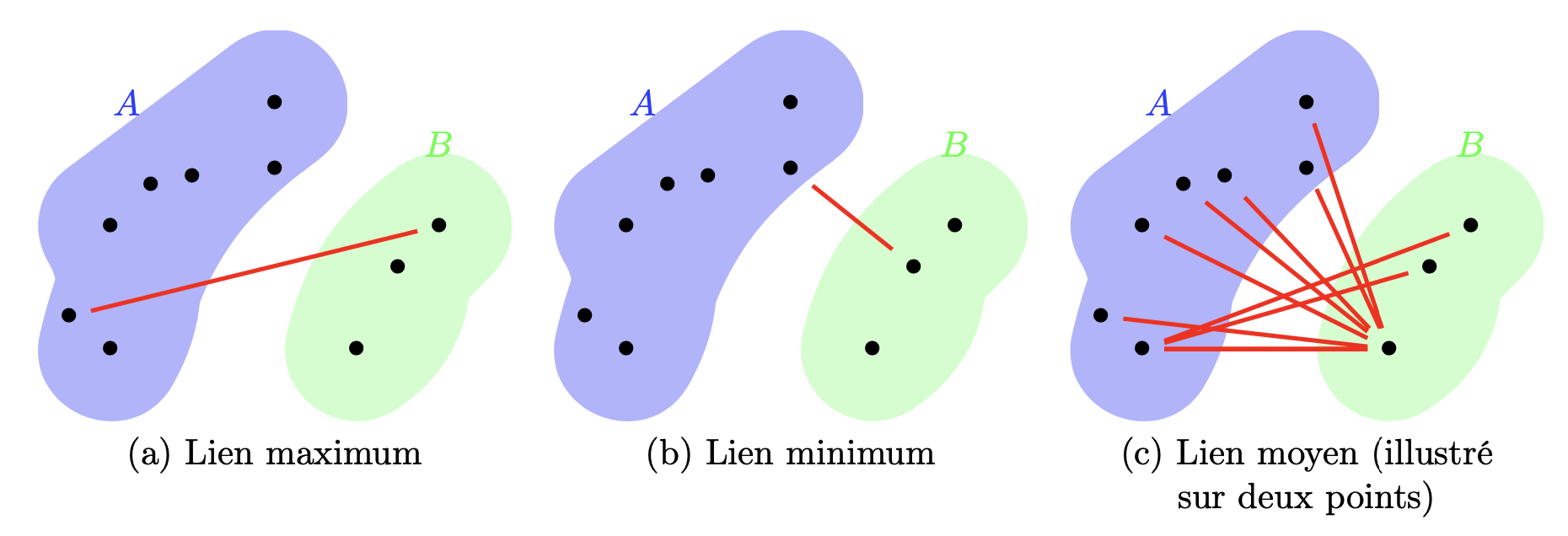
Il existe de nombreux critères d’agrégation, mais les plus utilisés sont les suivants :
critère du lien commun : \(D_{min}(A,B)=\displaystyle\min_{i\in A,j\in B}\delta_{ij}\)
critère du lien maximum: \(D_{max}(A,B)=\displaystyle\max_{i\in A,j\in B}\delta_{ij}\)
critère du lien moyen : \(D_{moy}(A,B)=\frac{\displaystyle\sum_{i\in A}\displaystyle\sum_{j\in B}\delta_{ij}}{|A||B|}\)
Formule de récurrence de Lance et Williams#
Pour les trois critères d’agrégation précédents, il existe des relations de simplification du calcul des distances entre classes essentielles pour la mise en place pratique de l’algorithme de classification ascendante :
\(D_{min}(A,B\cup C)=min(D_{min}(A,B),D_{min}(A,C))\)
\(D_{max}(A,B\cup C)=max(D_{max}(A,B),D_{max}(A,C))\)
\(D_{moy}(A,B\cup C)=\frac{|B|D_{moy}(A,B)+|C|D_{moy}(A,C)}{|B|+|C|}\)
Critère de Ward#
Lorsque l’ensemble \(\Omega\) à classifier est mesuré par \(d\) variables quantitatives, il est possible de lui associer un nuage de points pondérés dans \(\mathbb{R}^d\) muni de la distance euclidienne. Généralement, les pondérations seront toutes égales à 1. Le critère d’agrégation le plus utilisé dans cette situation est alors le critère d’inertie de Ward :
\(D(A,B)=\frac{p_Ap_B}{p_A+p_B}\|({\bf g}(A),{\bf g}(B))\|_2^2\)
où \(p_E\) représente la somme des pondérations des éléments d’une classe \(E\) et \({\bf g}(E)\) est le centre de gravité d’une classe \(E\).
Propriétés d’optimalité#
La notion de hiérarchie indicée est équivalente à la notion d’ultramétrique. La classification hiérarchique ascendante transforme donc la mesure de dissimilarité \(d\) initiale en une mesure de dissimilarité \(\delta\) qui possède la propriété d’être une ultramétrique.
Le problème de la classification hiérarchique peut donc également se poser en ces termes : trouver l’ultramétrique \(\delta^*\) la plus proche de \(\delta\). Il reste à munir l’espace des mesures de dissimilarité sur \(\Omega\) d’une distance. On pourra utiliser, par exemple :
\(\Delta(\delta,\delta^**)=\displaystyle\sum_{i,j\in \Omega}(\delta_{ij}-\delta^*_{ij})^2\)
\(\Delta(\delta,\delta^**)=\displaystyle\sum_{i,j\in \Omega}|\delta_{ij}-\delta^*_{ij}|\)
Critère d’arrêt et partition#
L’ensemble des itérations peut être visualisé sous la forme d’un arbre, appelé dendrogramme. La figure suivante présente un exemple de dendrogramme en clustering hiérarchique descendant sur \(X = \{a, b, c, d, e\}\). La distance \(D\) n’est pas reportée
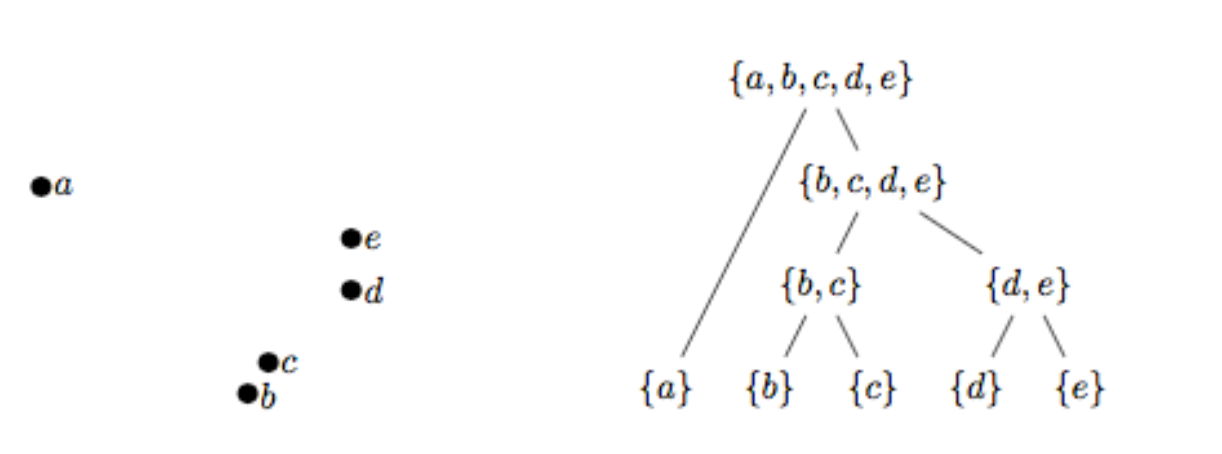
Le critère d’arrêt permet de déterminer la partition de \(X\) la plus appropriée. Ici encore, plusieurs choix sont possibles :
en fixant a priori un nombre de classes
en fixant une borne supérieure \(r\) pour \(D\), et en stoppant les itérations dès que les distances calculées par les liens dépassent \(r\). A noter que \(r\) peut être également calculé par \(r=\alpha max\{\delta(x,y),x,y\in X\}\) (critère dit « scale distance upper bound »).
en coupant le dendrogramme au saut de distance \(D\) maximal.
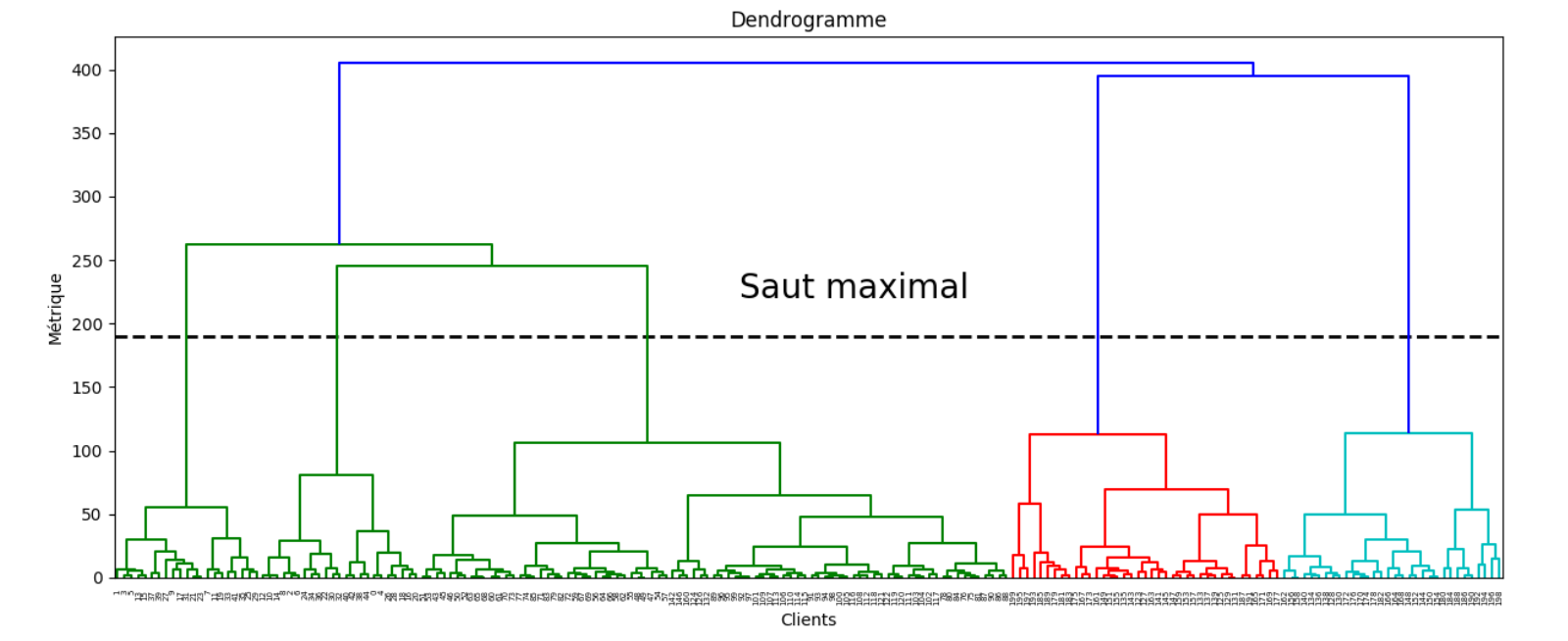
Utilisation des méthodes#
La première difficulté est le choix de la mesure de dissimilarité sur \(\Omega\) et du critère d’agrégation. Généralement, lorsque l’on dispose de variables quantitatives, le critère conseillé est le critère d’inertie. Ensuite, il est souvent nécessaire de disposer d’outils d’aide à l’interprétation et d’outils permettant de diminuer le nombre de niveaux de hiérarchie. Il est d’autre part conseillé d’utiliser conjointement d’autres méthodes d’analyse des données comme l’Analyse en Composantes Principales.
from IPython.display import Video
Video("videos/dendrogram.mp4",embed =True,width=800)
Exemple#
On étudie ici un jeu de données correspondant aux achats dans un supermarché. On cherche à caractériser les comportements des acheteurs en fonction de leurs revenus
import pandas as pd
df = pd.read_csv('./data/Mall_Customers.csv')
df.head(5)
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | |
|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 |
| 1 | 2 | Male | 21 | 15 | 81 |
| 2 | 3 | Female | 20 | 16 | 6 |
| 3 | 4 | Female | 23 | 16 | 77 |
| 4 | 5 | Female | 31 | 17 | 40 |
On affiche les données
import matplotlib.pyplot as plt
plt.figure(figsize=(16,5))
plt.subplot(121)
plt.title("Score/Revenu")
plt.xlabel ("Revenu annuel (k$)")
plt.ylabel ("Score d'achat")
plt.grid(True)
plt.scatter(df['Annual Income (k$)'],df['Spending Score (1-100)'],color='blue',edgecolor='k',alpha=0.6, s=50)
plt.subplot(122)
plt.title("Distribution des âges et des scores d'achat")
plt.xlabel ("Age")
plt.ylabel ("Score d'achat")
plt.grid(True)
plt.scatter(df['Age'],df['Spending Score (1-100)'],color='red',edgecolor='k',alpha=0.6, s=50)
plt.tight_layout()
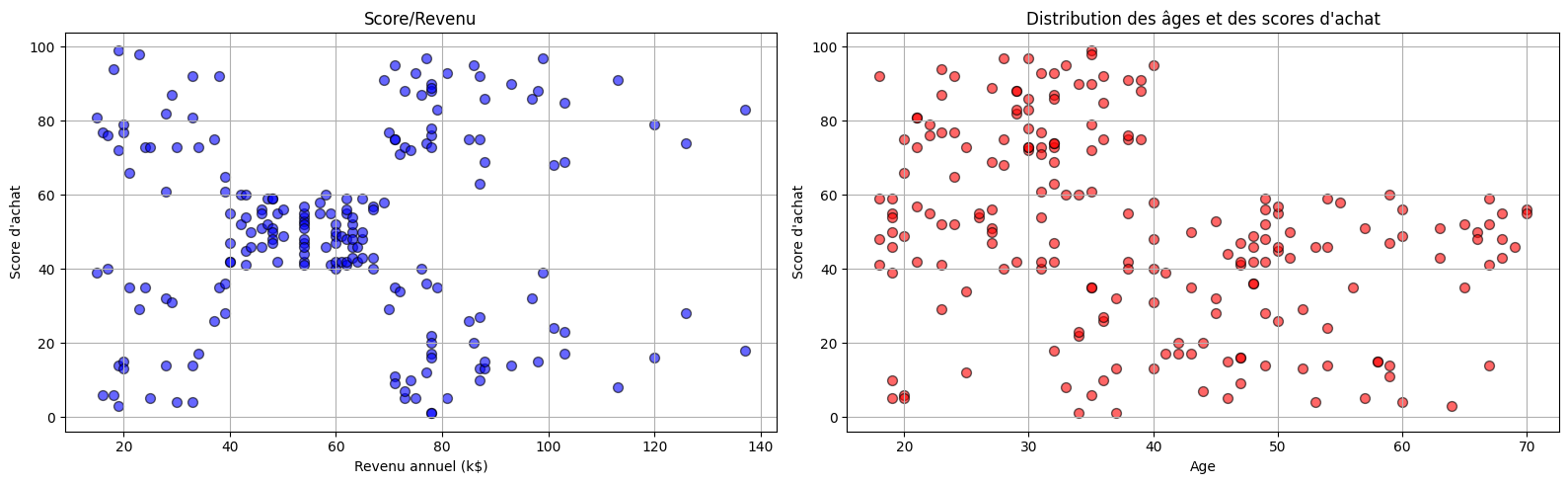
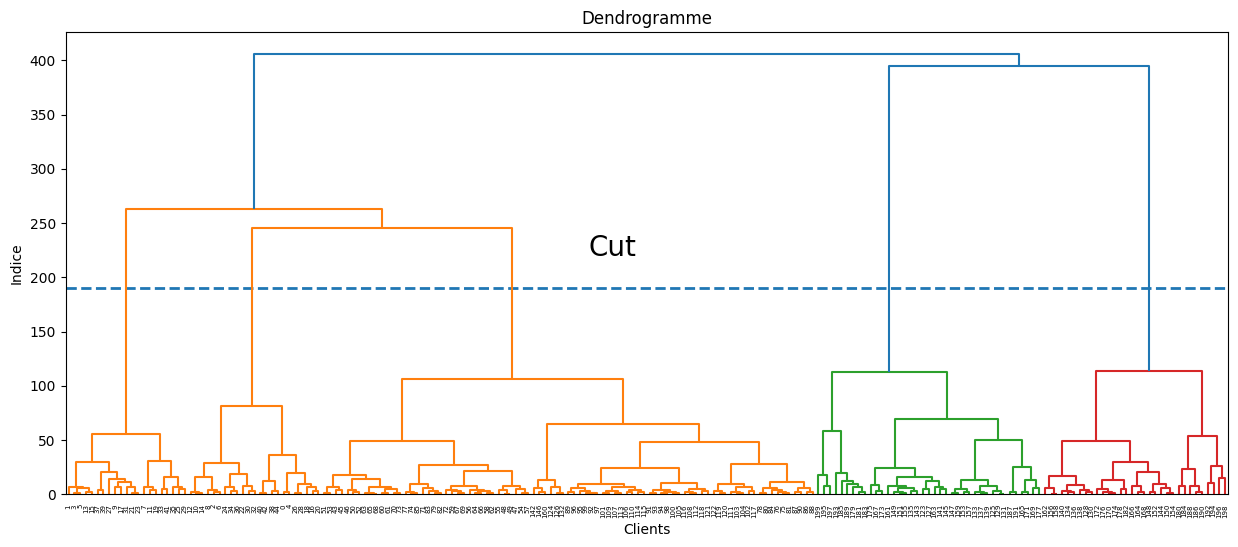
L’objectif est de trouver des catégories de population ayant les mêmes comportements d’achat. Le nombre de classes étant inconnu, la classification héararchique va permettre de donner des indications sur le nombre de groupes.
import scipy.cluster.hierarchy as sch
X = df.iloc[:,[3,4]].values
plt.figure(figsize=(15,6))
plt.title('Dendrogramme')
plt.xlabel('Clients')
plt.ylabel('Indice')
plt.hlines(y=190,xmin=0,xmax=2000,lw=2,linestyles='--')
plt.text(x=900,y=220,s='Cut',fontsize=20)
dendrogram = sch.dendrogram(sch.linkage(X, method = 'ward'))
plt.show()
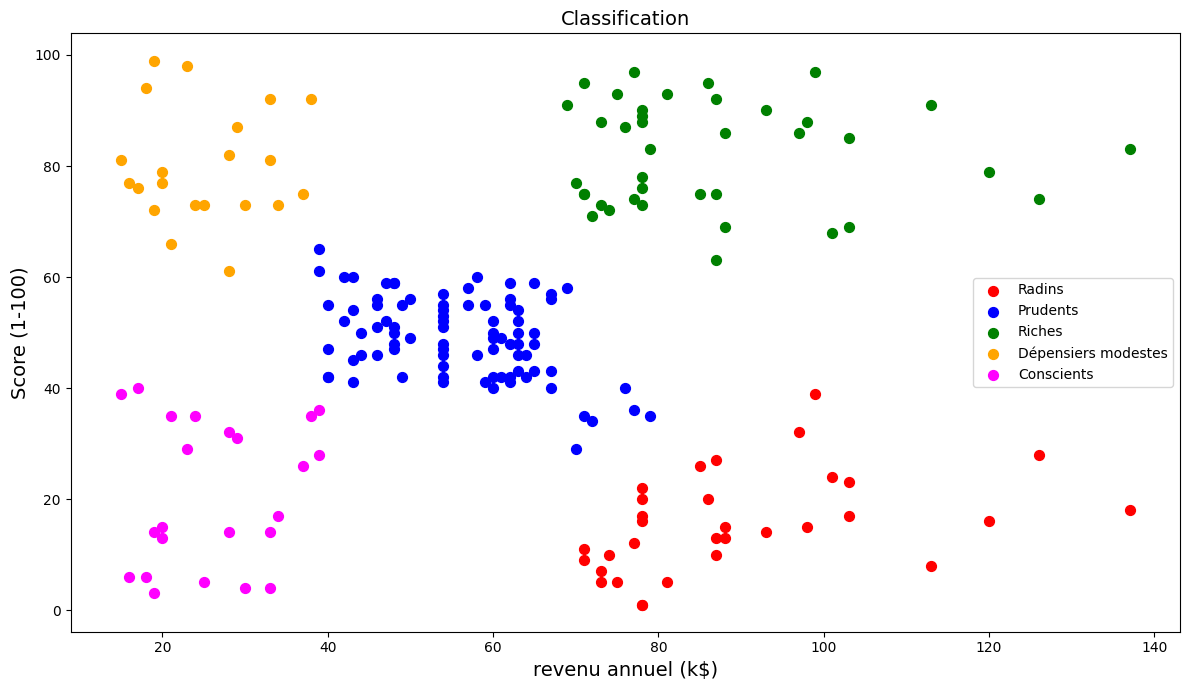
On projette ensuite le résultat de la classification
from sklearn.cluster import AgglomerativeClustering
model = AgglomerativeClustering(n_clusters = 5, metric = 'euclidean', linkage = 'ward')
y_model = model.fit_predict(X)
plt.figure(figsize=(12,7))
plt.scatter(X[y_model == 0, 0], X[y_model == 0, 1], s = 50, c = 'red', label = 'Radins')
plt.scatter(X[y_model == 1, 0], X[y_model == 1, 1], s = 50, c = 'blue', label = 'Prudents')
plt.scatter(X[y_model == 2, 0], X[y_model == 2, 1], s = 50, c = 'green', label = 'Riches')
plt.scatter(X[y_model == 3, 0], X[y_model == 3, 1], s = 50, c = 'orange', label = 'Dépensiers modestes')
plt.scatter(X[y_model == 4, 0], X[y_model == 4, 1], s = 50, c = 'magenta', label = 'Conscients')
plt.title('Classification',fontsize=14)
plt.xlabel ("revenu annuel (k$)",fontsize=14)
plt.ylabel ("Score (1-100)",fontsize=14)
plt.legend(loc='best')
plt.tight_layout()
Recherche de partitions#
Méthode des centres mobiles#
La méthode des centres mobiles est encore connue sous le nom de méthode de réallocation-centrage ou des k-means lorsque l’ensemble à classifier est mesuré par \(d\) variables. Ici, \(\Omega \in \mathbb{R}^d\) est muni de sa distance euclidienne \(\delta\). Pour simplifier la présentation, les pondérations des individus seront toutes égales à 1, mais la généralisation à des pondérations quelconques ne pose aucun problème.
Algorithme#
L’algorithme des centres-mobiles peut se définir ainsi :
Algorithm 8 (Algorithme des centres mobiles)
Entrée : \(\Omega\),\(g\), métrique
Sortie : Une partition de \(\Omega\)
Initialisation : tirage au hasard de \(g\) points de \(\Omega\) (centres initiaux des \(g\) classes)
Tant que (non convergence)
Étape E : Construction de la partition en affectant chaque point de \(\Omega\) à la classe dont il est le plus près du centre (en cas d’égalité, l’affectation se fait à la classe de plus petit indice).
Étape M : Les centres de gravité de la partition qui vient d’être calculée deviennent les nouveaux centres
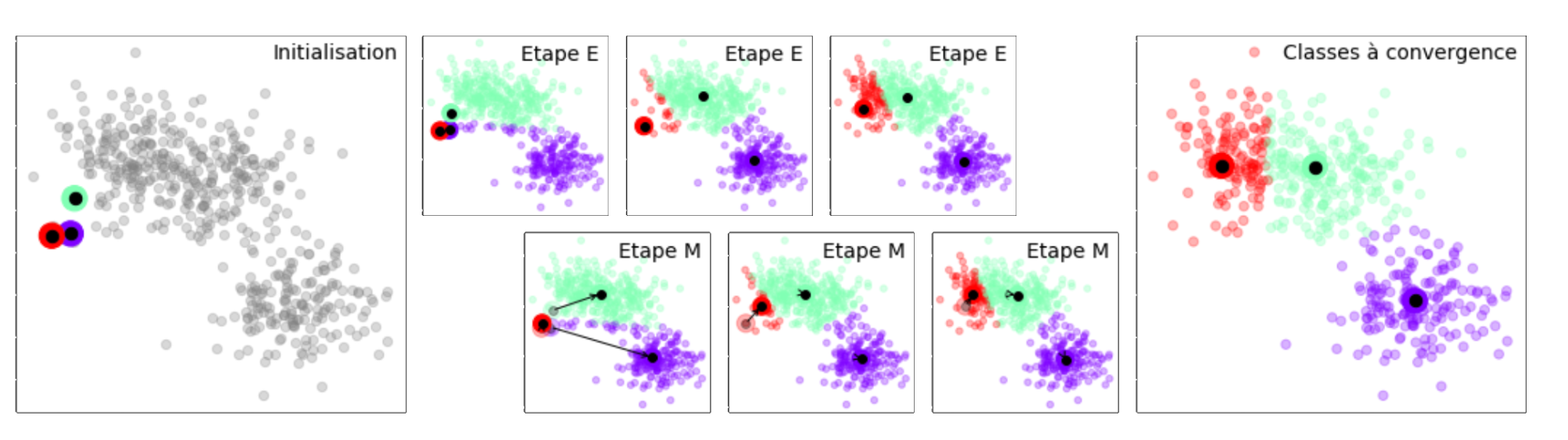
from IPython.display import Video
Video("videos/kmeans.mp4",embed =True,width=800)
L’initialisation des centres de classe étant aléatoire, il convient de répliquer l’algorithme plusieurs fois et de, par exemple, retenir la partition majoritaire. La figure suivante présente deux résultats des k-means, sur un même jeu de données (5 classes, 50 points par classes), avec une initialisation aléatoire différente.
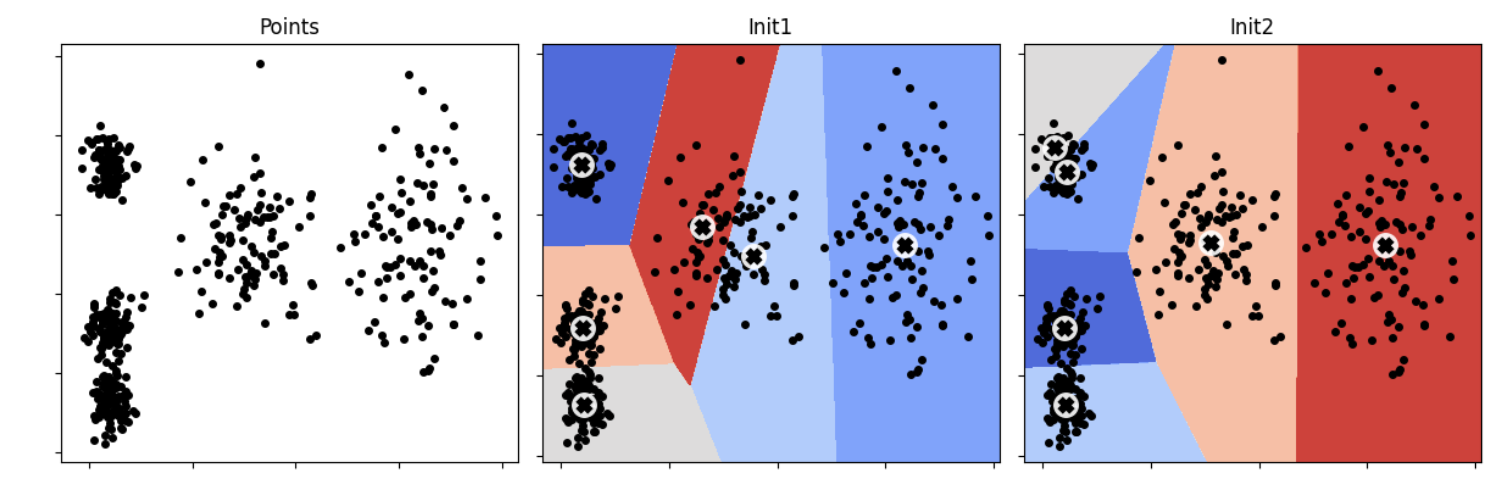
Critère et convergence#
La qualité d’un couple partition-centres est mesurée par la somme des inerties des classes par rapport à leur centre. On peut montrer qu’à chacune des deux étapes de l’algorithme, on améliore ce critère.
Lien avec la méthode de Ward#
La méthode des centres mobiles et la méthode de Ward optimisent toutes deux, à leur façon, le critère d’inertie intra-classe. Cette situation conduit à proposer des stratégies utilisant les deux approches comme, par exemple :
appliquer les centres-mobiles pour regrouper l’ensemble initial en un nombre « important » de classes
appliquer la méthode de Ward en partant de ces classes
rechercher quelques « bons » niveaux de la hiérarchie
éventuellement, appliquer de nouveau la méthode des centres-mobiles sur les partitions obtenues pour améliorer encore leur critère.
Généralisation : les nuées dynamiques#
L’idée de base consiste à remplacer les centres qui étaient des éléments de \(\mathbb{R}^d\) jouant le rôle de représentant ou encore de noyau de la classe par des éléments de nature très diverse adaptés au problème que l’on cherche à résoudre.
Formalisation#
On note \(L=\{\lambda_i\}\) l’ensemble des noyaux, \(D:\Omega\times L\rightarrow \mathbb{R}^+\) une mesure de ressemblance entre éléments de \(\Omega\) et de \(L\). L’objectif est alors de trouver la partition en \(g\) classes (\(g\) fixé a priori) de \(\Omega\) minimisant le critère \(\displaystyle\sum_{k}\displaystyle\sum_{x\in P_k}D(x,\lambda_k)\)
Cette minimisation est réalisée de façon alternée, comme pour les centres mobiles.
Choix du nombre de classes#
En général, le critère n’est pas indépendant du nombre de classes. Par exemple, le critère de l’inertie s’annule pour la partition triviale pour laquelle chaque point forme une classe. Il s’agit donc de la meilleure partition. Il est donc nécessaire de fixer a priori le nombre de classes. Pour résoudre ce problème très difficile, plusieurs solutions sont utilisées :
on a une idée du nombre de classes désirées
on recherche la meilleure partition pour plusieurs nombres de classes et on étudie la décroissance du critère en fonction du nombre de classes (méthode du coude)
on définit une fonction \(f(\Omega)\) qui rend le critère indépendant du nombre de classes
on ajoute des contraintes supplémentaires (nombre d’individus par classe, volume d’une classe…). C’est l’option retenue par la méthode Isodata
on effectue des tests statistiques sur les classes
Quelques variantes#
K-means++#
Plutôt que d’initialiser les centres de manière aléatoire, l’algorithme K-means++ propose de partitionner \(\Omega=\{\mathbf x_1\cdots \mathbf x_n\}\) selon l’algorithme suivant :
Tirer uniformément le premier centre de classe \(c_1\) dans \(\Omega\)
Pour \(i\in[\![2,g]\!]\), choisir \(\mathbf{c_i}\) à partir de \(\mathbf x_i\) selon la probabilité \(D(\mathbf{x}_i)^2\) / \(\displaystyle\sum\limits_{j=1}^{m}{D(\mathbf{x}_j)}^2\) où \(D(\mathbf{x}_i)\) est la distance entre \(\mathbf{x}_i\) et le centre de classe le plus proche déjà choisi. Ceci assure de tirer des centres de classe éloignés avec forte probabilité.
Accélération des k-means#
L’algorithme original peut être amélioré de manière significative en évitant les calculs de distances non nécessaires. En exploitant l’inégalité triangulaire, et en conservant les bornes inférieures et supérieures des distances entre les points et les centres de classe, l’algorithme correspondant est performant, y compris pour de grandes valeurs de \(k\) (Algorithm 9).
Algorithm 9 (Accélération des k-means)
Entrée : \(\Omega, g\)
Sortie : \(P\) une partition de \(X\) en \(g\) classes
Initialisation : tirage au hasard de \(g\) points \(C =\{\mathbf {c_1}\cdots \mathbf {c_g\}}\)
Pour \(\mathbf x\in \Omega,\mathbf c\in C\)
\(l(\mathbf x,\mathbf c)=0\)
Pour tout \(\mathbf x\in \Omega\)
Affecter \(\mathbf x\) à la classe du centre le plus proche : \(\mathbf c(x) = Arg \displaystyle\min_{\mathbf c\in C} \delta(\mathbf x,\mathbf c)\)
A chaque calcul de \(\delta(\mathbf x,\mathbf c)\),\( l(\mathbf x,\mathbf c)=\delta(\mathbf x,\mathbf c)\)
\(u(\mathbf x,\mathbf c)=\displaystyle\min_{\mathbf c\in C} \delta(\mathbf x,\mathbf c)\)
Tant que (non convergence)
Pour tout \(\mathbf c,\mathbf {c'}\in C\) calculer \(\delta (\mathbf c,\mathbf {c'})\)
Pour tout \(\mathbf c\) \(s(c)= \frac{1}{2}\displaystyle\min_{\mathbf {c'}\neq \mathbf c} \delta(\mathbf c,\mathbf {c'})\)
Identifier les \(\mathbf x\) tels que \(u(\mathbf x)\leq s(\mathbf c(\mathbf x))\)
Pour tout \(\mathbf x\in \Omega,\mathbf c\in C\) tels que \(\mathbf c\neq \mathbf c(\mathbf x)\) et \(u(\mathbf x)>l(\mathbf x,\mathbf c)\) et \(u(\mathbf x)>\frac{1}{2}\delta(\mathbf c(\mathbf x),\mathbf c)\)
Si \(r(\mathbf x)\)
Calculer \(\delta(\mathbf c(\mathbf x),\mathbf x)\)
\(r(\mathbf x)=Faux\)
Sinon
\(\delta(\mathbf c(\mathbf x),\mathbf x)=u(\mathbf x)\)
Si \(\delta(\mathbf c(\mathbf x),\mathbf x)>l(\mathbf x,\mathbf c)\) ou \(\delta(\mathbf c(\mathbf x),\mathbf x)>\frac{1}{2}\delta(\mathbf c(\mathbf x),\mathbf c)\)
Calculer \(\delta(\mathbf x,\mathbf c)\)
Si \(\delta(\mathbf x,\mathbf c)<\delta(\mathbf c(\mathbf x),\mathbf x)\)
\(\mathbf c(\mathbf x)= \mathbf c\)
Pour tout \(\mathbf c\in C\)
\(\mathbf m(\mathbf c)\) : centre de masse des points de \(\Omega\) plus proches de \(\mathbf c\)
Pour tout \(\mathbf x\in \Omega,\mathbf c\in C\)
\(l(\mathbf x,\mathbf c)=max\left (l(\mathbf x,\mathbf c)-\delta(\mathbf m(\mathbf c),\mathbf c),0 \right )\)
Pour tout \(\mathbf x\in \Omega\)
\(u(\mathbf x)=u(\mathbf x)+\delta(\mathbf m(\mathbf c(\mathbf x)),\mathbf c(\mathbf x))\)
\(r(\mathbf x)=Vrai\)
Pour tout \(\mathbf c\in C\)
\(\mathbf c = \mathbf m(\mathbf c)\)
k-means à mini batchs#
Il est également possible d’appliquer une optimisation par mini-batchs dans l’algorithme des k-means (Algorithm 10).
Algorithm 10 (Accélération des k-means)
Entrée : \(\Omega, g\), \(b\) taille des batchs
Sortie : \(P\) une partition de \(X\) en \(g\) classes
Initialisation : tirage au hasard de \(g\) points \(C =\{\mathbf {c_1}\cdots \mathbf {c_g\}}\)
\(\mathbf v=0\in\mathbb{R}^g\)
Tant que non convergence
\(\mathcal{B}\leftarrow\) batch de \(b\) exemples tirés de \(X\)
Pour tout \(\mathbf x\in \mathcal{B}\)
Affecter \(\mathbf x\) à la classe du centre le plus proche \(\mathbf T(\mathbf x)\)
Pour tout \(\mathbf x\in \mathcal{B}\)
\(\mathbf c = \mathbf T(\mathbf x)\)
\(v_c = v_c + 1\)
\(\eta = \frac{1}{v_c}\)
\(\mathbf c = (1-\eta)\mathbf c + \eta \mathbf x\)
Exemple#
On génère des données
from sklearn.datasets import make_blobs
import numpy as np
import matplotlib.pyplot as plt
nb_classes = 3
center = np.array(
[[ 3, 0],[1 , 1],[3, 4]])
cluster_std = np.array([0.8, 0.3, 1])
X, y = make_blobs(n_samples=500,centers=center,cluster_std = cluster_std, random_state=42)
plt.figure(figsize=(5,5))
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.tight_layout()
plt.tick_params(labelbottom=False)
plt.tick_params(labelleft=False)

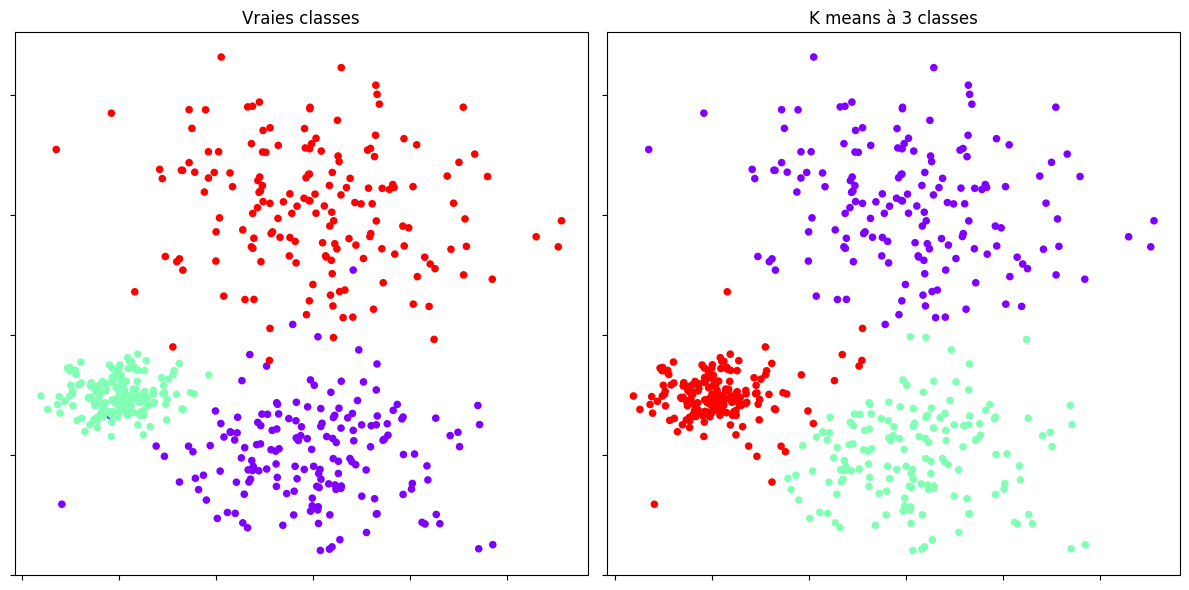
Puis on applique l’algorithme des \(k\)-means.
from sklearn.cluster import KMeans
model = KMeans(n_clusters=nb_classes,n_init=10)
plt.figure(figsize=(12,6))
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1],c=y, s=30,linewidths=0,cmap=plt.cm.rainbow)
plt.title("Vraies classes")
plt.tick_params(labelbottom=False)
plt.tick_params(labelleft=False)
plt.subplot(122)
model.fit(X)
plt.scatter(X[:, 0], X[:, 1], c=model.labels_, s=30,linewidths=0, cmap=plt.cm.rainbow)
plt.title("K means à {0:d} classes".format(nb_classes))
plt.tick_params(labelbottom=False)
plt.tick_params(labelleft=False)
plt.tight_layout()
Modèles de mélange#
Les modèles de mélange supposent que les données proviennent d’un mélange de distributions (généralement gaussiennes), et l’objectif est alors d’estimer les paramètres du modèle de mélange en maximisant la fonction de vraisemblance pour les données. L’optimisation directe de la fonction de vraisemblance dans ce cas n’est pas une tâche simple, en raison des contraintes nécessaires sur les paramètres et de la nature complexe de la fonction de vraisemblance, qui présente généralement un grand nombre de maxima locaux et de points de selle. Une méthode courante pour estimer les paramètres du modèle de mélange est l’algorithme EM.
Définition#
Soient \(\mathcal S = \{\mathbf X_1\cdots X_n\}\) \(n\) vecteurs aléatoires i.i.d. à valeur dans \(\mathcal X\subset \mathbb{R}^d\) , chaque \(\mathbf X_i\) étant distribué selon
où \(\Phi_i,i\in[\![1,K]\!]\) sont des densités de probabilité sur \(\mathcal X\) et les \(w_i\) sont des poids positifs, sommant à 1. \(g\) peut être interprétée comme suit : soit \(Z\) une variable aléatoire discrète prenant les valeurs \(i\in[\![1,K]\!]\) avec probabilité \(w_i\), et soit \(\mathbf X\) un vecteur aléatoire dont la distribution conditionnelle, étant donnée \(Z=z\) est \(\Phi_z\). Alors
et la distribution marginale de \(\mathbf X\) est calculée en sommant sur \(z\) les probabilités jointes.
Un vecteur aléatoire \(\mathbf X\) suivant \(g\) peut donc être simulé d’abord en tirant \(Z\) suivant \(P(Z=z)=w_z,z\in[\![1,K]\!]\), puis en tirant \(\mathbf X\) suivant \(\Phi_Z\). La famille \(\mathcal S\) ne contenant que les \(\mathbf X_i\), les \(Z_i\) sont des variables latentes, interprétées comme les étiquettes cachées des classes auxquelles les \(\mathbf X_i\) appartiennent.
Typiquement, les \(\Phi_k\) sont des lois paramétriques. Classiquement ce sont des lois gaussiennes \(\mathcal N(\boldsymbol \mu_k,\boldsymbol \Sigma_k)\) et donc en rassemblant tous les paramètres des lois, incluant les \(w_k\), dans un vecteur de paramètre \(\boldsymbol \theta = (\mu_k,\boldsymbol \Sigma_k,w_k,k\in[\!1,K]\!])\), on peut écrire
où \(s=(\mathbf x_1\cdots \mathbf x_n)\) dénote une réalisation de \(\mathcal S\).
On estime alors \(\boldsymbol\theta\) en maximisant la log vraisemblance
ce qui est en général complexe, la fonction \(\ell\) admettant de nombreux extrema locaux.
Algorithme EM#
Plutôt que d’optimiser \(\ell\) directement depuis les données \(s\), l’algorithme EM (Algorithm 11) augmente d’abord les données des variables latentes (les étiquettes \(\mathbf z=(z_1\cdots z_n)\) des classes). L’idée est que \(s\) est uniquement la partie observée des données aléatoires \((\mathcal S,\mathbf Z)\) générées d’abord en tirant \(Z\) suivant \(P(Z=z)\), puis en tirant \(\mathbf X\) suivant \(\Phi_z\), de sorte à avoir
Ainsi, la log vraisemblance des données complètes, en général plus facile à optimiser, est
Cependant, les \(z\) ne sont pas observées et \(\bar\ell\) ne peut être évaluée. Dans l’étape E de l’algorithme EM, \(\bar\ell\) est remplacée par \(\mathbb{E}_p \bar\ell(\boldsymbol \theta |s,\mathbf Z)\), où l’indice \(p\) indique que \(\mathbf Z\) est distribuée selon la distribution conditionnelle de \(\mathbf Z\) étant donnée \(\mathcal S=s\), soit
Remark 23
\(p(z)\) est de la forme \(p_1(z_1)\cdots p_n(z_n)\) de telle sorte que, étant donné \(\mathcal S=s\), les composantes de \(\mathbf Z\) sont deux à deux indépendantes.
Algorithm 11 (Algorithmes EM)
Entrée : \(s,\boldsymbol\theta^{(0)}\)
Sortie : Approximation de la log vraisemblance maximale
\(i=1\)
Tant que (not stop)
Etape E : Trouver \(p^{(i)}(z) = g(s|s,\boldsymbol\theta^{(i-1)})\) et \(Q^{(i)}(\boldsymbol\theta)=\mathbb{E}_p \bar\ell(\boldsymbol \theta |s,\mathbf Z)\)
Etape M : \(\boldsymbol\theta^{(i)} = Arg \displaystyle\max_{\boldsymbol\theta} Q^{(i)}(\boldsymbol\theta)\)
\(i = i+1\)
Retourner \(\boldsymbol\theta{(i)}\)
Dans l”Algorithm 11, un critère d’arrêt est par exemple
Sous certaines conditions, la suite des \(\ell(\boldsymbol\theta{(i)}|s)\) converge vers un maximum local de la log vraisemblance \(\ell\). La convergence vers le maximum global dépend bien sûr du choix de \(\boldsymbol\theta^{(0)}\), de sorte qu’une stratégie possible est d’exécuter plusieurs fois l’algorithme avec des initialisations différentes.
Dans le cas d’un mélange gaussien, \(\Phi_k=\mathcal N(\boldsymbol\mu_k,\boldsymbol\Sigma_k),k\in[\![1,K]\!]\). Si \(\boldsymbol\theta^{(i-1)}\) est le vecteur optimal à l’itération courante, constitué des poids \(w_k^{(i-1)}\), des vecteurs moyenne \((\boldsymbol\mu_k)^{(i-1)}\) et des matrices de covariances \((\boldsymbol\Sigma_k)^{(i-1)}\), alors on détermine \(p^{(i)}\), la distribution de \(\mathbf Z\) conditionnelement à \(\mathcal S=s\), pour le paramètre \(\boldsymbol\theta^{(i-1)}\). Puisque les composantes de \(\mathbf Z\) étant donné \(\mathcal S=s\) sont indépendantes, il suffit de spécifier la distribution discrète \(p_j^{(i)}\) de chaque \(Z_j\), étant données l’observation \(\mathbf X_j=\mathbf x_j\), calculée à l’aide de la forule de Bayes
Alors
Pour l’étape E
où les \(Z_j\) sont indépendants et distribués selon \(p_j^{(i)}\).
Pour l’étape M, on maximise
sous la contrainte \(\displaystyle\sum_{k=1}^K w_k=1\).
En utilisant une relxation lagrangienne, et le fait que \(\displaystyle\sum_{k=1}^K p_j^{(i)}(k)=1\) on trouve pour tout \(k\in[\![1,K]\!]\)
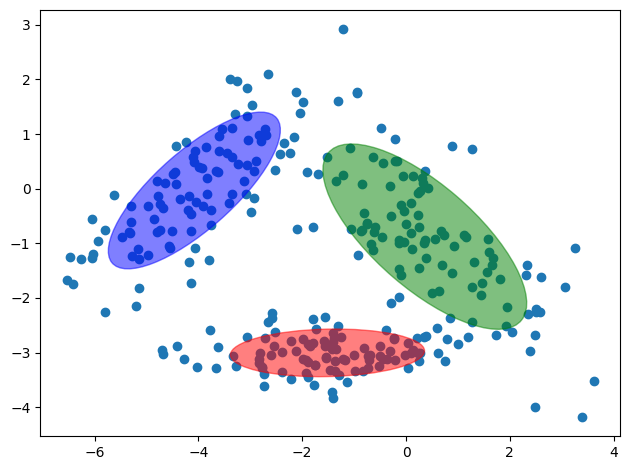
import numpy as np
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
import matplotlib
X = np.genfromtxt('./data/mixture.csv', delimiter=',')
K = 3
n, d = X.shape
# Paramètres initiaux
W = np.array([[1/3,1/3,1/3]]) # poids
M = np.array([[-2.0,-4,0],[-3,1,-1]]) # Moyennes
C = np.zeros((3,2,2)) # Co
C[:,0,0] = 1
C[:,1,1] = 1
p = np.zeros((3,300))
for i in range(0,100):
# Etape E
for k in range(0,K):
mvn = multivariate_normal( M[:,k].T, C[k,:,:] )
p[k,:] = W[0,k]*mvn.pdf(X)
# Etape M
p = p/sum(p,0)
W = np.mean(p,1).reshape(1,3)
for k in range(0,K):
M[:,k] = (X.T @ p[k,:].T)/sum(p[k,:])
xm = X.T - M[:,k].reshape(2,1)
C[k,:,:] = xm @ (xm*p[k,:]).T/sum(p[k,:])
fig = plt.subplot(1, 1, 1)
plt.scatter(X[:,0],X[:,1])
c = ['r','b','g']
for i in range(0,3):
v, w = np.linalg.eigh(C[i,:,:])
v = 2.0 * np.sqrt(2.0) * np.sqrt(v)
u = w[0] / np.linalg.norm(w[0])
angle = np.arctan(u[1] / u[0])
angle = 180.0 * angle / np.pi
ell = matplotlib.patches.Ellipse(M[:,i], v[0], v[1], angle=180.0 + angle, color=c[i])
ell.set_clip_box(fig.bbox)
ell.set_alpha(0.5)
fig.add_artist(ell)
plt.tight_layout()
plt.show()
Influence des matrices de covariance#
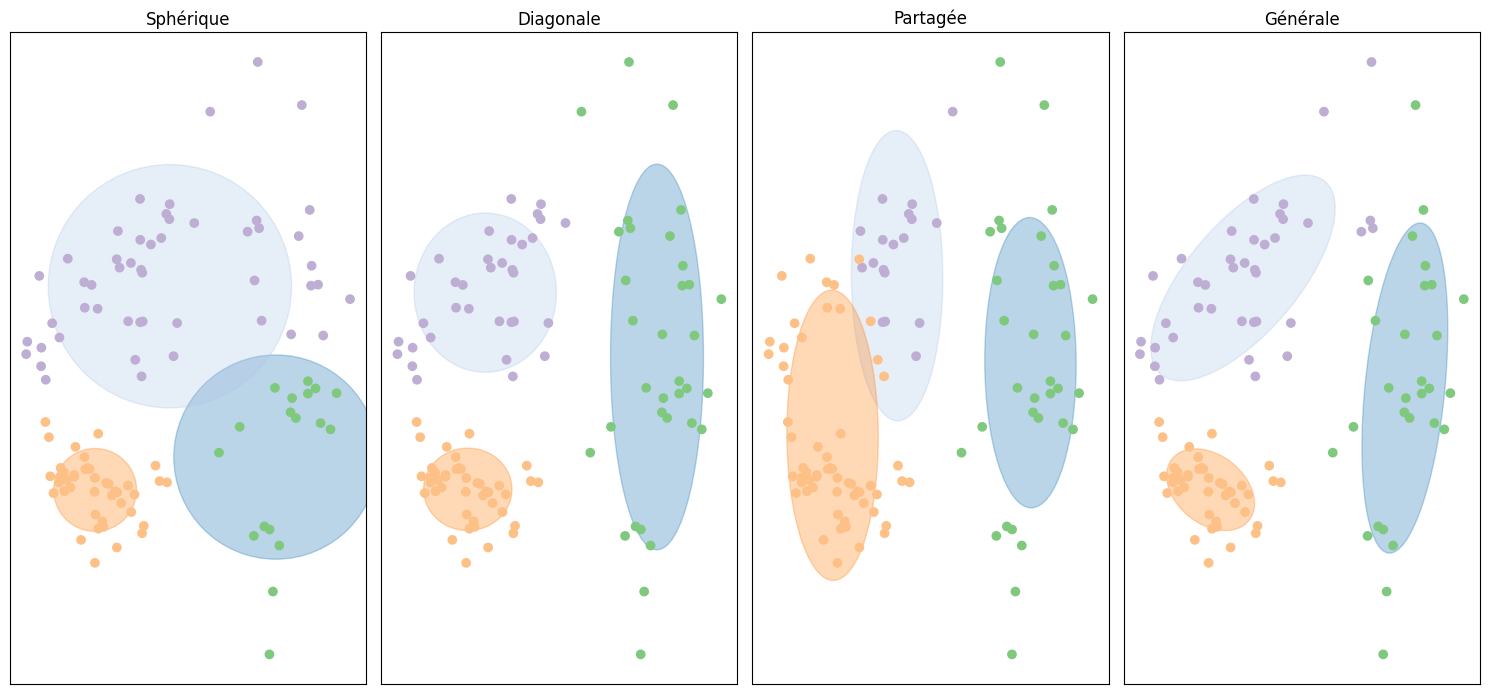
Dans le cas multivarié, les descripteurs peuvent être dépendants ou non, introduisant des termes de covariance dans la matrice du même nom. Ainsi, cette dernière peut être pleine (et identique pour toutes les composantes ou non), ou diagonale (avec les variances des descripteurs égales ou non).
La matrice de covariance peut alors prendre plusieurs formes :
chaque composante gaussienne a sa matrice de covariance propre, de forme générale
chaque composante gaussienne a sa matrice de covariance propre, diagonale
toutes les composantes gaussiennes ont la même matrice de covariance
chaque composante gaussienne a une matrice de covariance diagonale, à terme diagonaux égaux
from sklearn.mixture import GaussianMixture
import matplotlib.pyplot as plt
import matplotlib
def Ellipses(gmm, ax):
for n in range(gmm.n_components):
if gmm.covariance_type == 'full':
covariances = gmm.covariances_[n]
elif gmm.covariance_type == 'diag':
covariances = np.diag(gmm.covariances_[n])
elif gmm.covariance_type == 'tied':
covariances = gmm.covariances_
elif gmm.covariance_type == 'spherical':
covariances = np.eye(gmm.means_.shape[1]) * gmm.covariances_[n]
v, w = np.linalg.eigh(covariances)
u = w[0] / np.linalg.norm(w[0])
angle = 180 * np.arctan2(u[1], u[0]) / np.pi
v = 2. * np.sqrt(2.) * np.sqrt(v)
ell = matplotlib.patches.Ellipse(gmm.means_[n], v[0], v[1],
angle=180 + angle, color=plt.cm.tab20(n))
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.3)
ax.add_artist(ell)
rnd = np.random.RandomState(4)
# Données
A = rnd.normal(size=(40, 2)) + rnd.normal(scale=10, size=(1, 2))
B = rnd.normal(scale=(1, 5), size=(30, 2)) + rnd.normal(scale=(15, 1), size=(1, 2))
C = np.dot(rnd.normal(scale=(1, 2), size=(40, 2)), [[1, -1], [1, 1]]) + rnd.normal(scale=(10, 1), size=(1, 2))
X = np.vstack([A, B, C])
gmm = [GaussianMixture(n_components=3, covariance_type=cov_type, max_iter=20, random_state=0)
for cov_type in ['spherical', 'diag', 'tied', 'full']]
n_estimators = len(gmm)
fig, axes = plt.subplots(1, 4, figsize=(15, 10))
titles = ("Sphérique", "Diagonale","Partagée", "Générale")
for ax, title, gmmi in zip(axes, titles, gmm):
gmmi.fit(X)
Ellipses(gmmi, ax)
pred = gmmi.predict(X)
ax.scatter(X[:, 0], X[:, 1], c=plt.cm.Accent(pred))
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
ax.set_aspect("equal")
plt.tight_layout()
Comparaison aux k-means#
Par défaut (métrique euclidienne), les k-means évaluent des nuages sphériques.
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_blobs
n_samples = 500
# Nuages de points allongés
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
transformation = [[0.6, -0.6], [-0.5, 0.8]]
X = np.dot(X, transformation)
fig, axes = plt.subplots(1, 2, figsize=(6, 3))
for ax, model in zip(axes, [GaussianMixture(n_components=3), KMeans(n_clusters=3,n_init='auto')]):
model.fit(X)
ax.scatter(X[:, 0], X[:, 1], c=plt.cm.Accent(model.predict(X)), alpha=.6)
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(type(model).__name__)
plt.tight_layout()

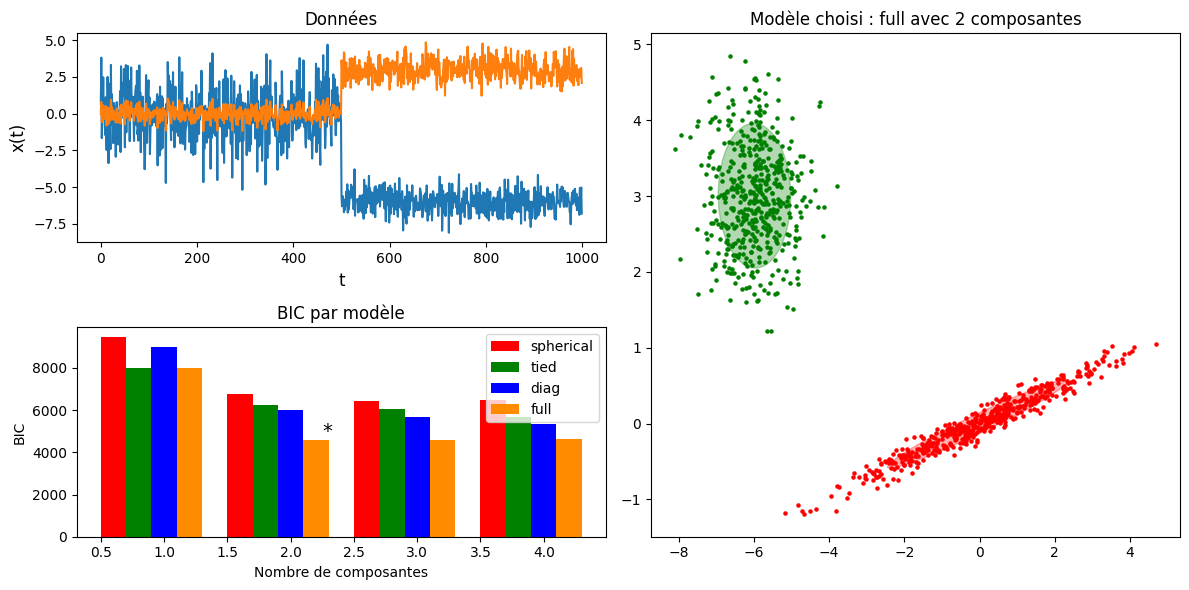
Estimation du nombre de classes#
En optimisant un critère statistique, il est possible de trouver, dans le cas où le nombre de composantes \(k\) est inconnu, la meilleure valeur par rapport à ce critère. Il est de plus possible, pour les matrices de covariance, d’estimer la meilleure forme des nuages de points, et d’adapter la matrice en fonction de cette forme.
Dans le code qui suit, on estime à la fois les matrices de covariance les plus adaptées et le nombre de composantes \(k\), en optimisant le critère d’information Bayésien \(BIC = -2ln(L) + pln(n)\), où \(L\) est la vraisemblance du modèle estimé, \(n\) le nombre d’observations, et \(p\) le nombre de paramètres libres du modèle.
import itertools
from scipy import linalg
from sklearn.mixture import GaussianMixture
import matplotlib
n_samples = 500
fig = plt.figure(figsize=(12, 6))
# Données
ax1 = plt.subplot(221)
np.random.seed(0)
C = np.array([[0., -0.1], [1.7, .4]])
X = np.r_[np.dot(np.random.randn(n_samples, 2), C),
.7 * np.random.randn(n_samples, 2) + np.array([-6, 3])]
ax1.plot(X)
ax1.set_title('Données', fontsize=12)
ax1.set_xlabel('t', fontsize=12)
ax1.set_ylabel('x(t)', fontsize=12)
# Critère BIC en fonction des composantes et du modèle de covariance
ax2 = plt.subplot(223)
lowest_bic = np.inf
bic = []
n_components_range = range(1, 5)
cv_types = ['spherical', 'tied', 'diag', 'full']
for cv_type in cv_types:
for n_components in n_components_range:
gmm = GaussianMixture(n_components=n_components,
covariance_type=cv_type)
gmm.fit(X)
bic.append(gmm.bic(X))
if bic[-1] < lowest_bic:
lowest_bic = bic[-1]
best_gmm = gmm
bic = np.array(bic)
color_iter = itertools.cycle(['red', 'green', 'blue',
'darkorange'])
bars = []
for i, (cv_type, color) in enumerate(zip(cv_types, color_iter)):
xpos = np.array(n_components_range) + .2 * (i - 2)
bars.append(plt.bar(xpos, bic[i * len(n_components_range):
(i + 1) * len(n_components_range)],
width=.2, color=color))
ax2.set_title('BIC par modèle')
xpos = np.mod(bic.argmin(), len(n_components_range)) + .65 +\
.2 * np.floor(bic.argmin() / len(n_components_range))
plt.text(xpos, bic.min() * 0.97 + .03 * bic.max(), '*', fontsize=14)
ax2.set_xlabel('Nombre de composantes')
ax2.set_ylabel('BIC')
ax2.legend([b[0] for b in bars], cv_types)
# Affichage classes
ax3 = plt.subplot(122)
Y_ = best_gmm.predict(X)
for i, (mean, cov, color) in enumerate(zip(best_gmm.means_, best_gmm.covariances_,
color_iter)):
v, w = linalg.eigh(cov)
if not np.any(Y_ == i):
continue
plt.scatter(X[Y_ == i, 0], X[Y_ == i, 1], 5,color=color)
# Ellipse modélisant la composante gaussienne
angle = 180. * np.arctan2(w[0][1], w[0][0]) / np.pi
v = 2. * np.sqrt(2.*v)
ax3.add_artist(matplotlib.patches.Ellipse(mean, v[0], v[1], angle = 180. + angle, color=color,alpha=.3))
t = "Modèle choisi : "+ best_gmm.covariance_type +" avec "+ str(best_gmm.n_components)+" composantes"
ax3.set_title(t)
plt.subplots_adjust(hspace=.35, bottom=.02)
plt.tight_layout()
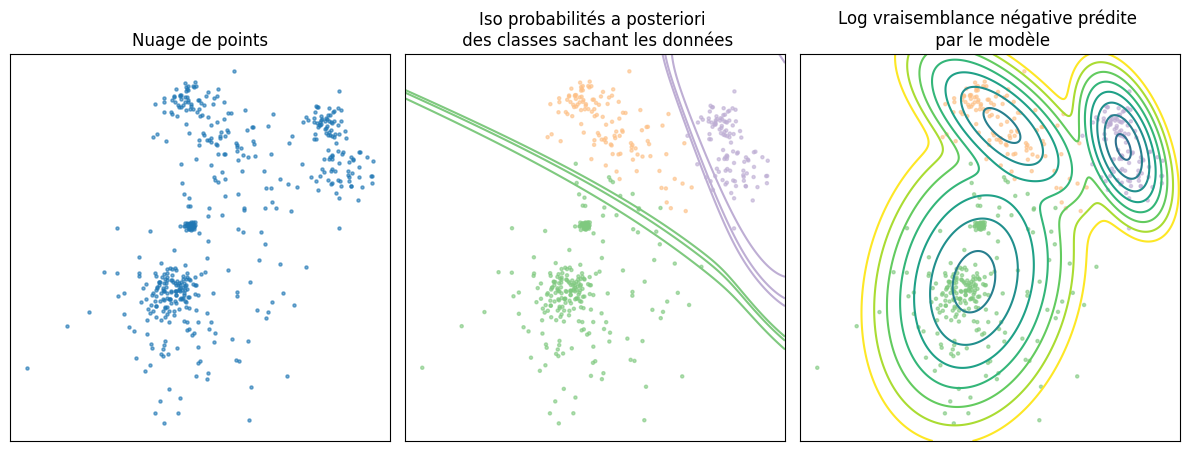
Modèles de mélange et estimation#
Les modèles de mélange sont également utilisés en estimation de densité. Il suffit pour cela :
d’échantillonner la composante \(C_i\) désirée, selon la distribution \(P(C_i)=\pi_i\)
d’échantillonner un \(\mathbf x\) de la distribution de la composante \(C_i\), selon \({\cal N}(x|\hat{\theta}_i)\)
from matplotlib.colors import LogNorm
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
rng = np.random.RandomState(3)
Xi, yi = make_blobs(n_samples=500, centers=10, random_state=rng, cluster_std=[rng.gamma(1.5) for i in range(10)])
gmmi = GaussianMixture(n_components=3)
gmmi.fit(Xi)
assignment = gmmi.predict(Xi)
plt.figure(figsize=(12, 6))
plt.subplot(131)
plt.scatter(Xi[:, 0], Xi[:, 1], s=5, alpha=.6)
plt.gca().set_aspect("equal")
xlim = plt.xlim()
ylim = plt.ylim()
plt.xticks(())
plt.yticks(())
plt.title("Nuage de points")
plt.subplot(132)
xs = np.linspace(xlim[0], xlim[1], 1000)
ys = np.linspace(ylim[0], ylim[1], 1000)
xx, yy = np.meshgrid(xs, ys)
pred = gmmi.predict_proba(np.c_[xx.ravel(), yy.ravel()])
plt.scatter(Xi[:, 0], Xi[:, 1], s=5, alpha=.6, c=plt.cm.Accent(assignment))
plt.gca().set_aspect("equal")
plt.xticks(())
plt.yticks(())
levels = [.9, .95, .99, 1]
for color, component in zip(range(k), pred.T):
plt.contour(xx, yy, component.reshape(xx.shape), colors=[plt.cm.Accent(color)], levels=levels)
plt.title("Iso probabilités a posteriori \n des classes sachant les données")
plt.subplot(133)
scores = -gmmi.score_samples(np.c_[xx.ravel(), yy.ravel()])
plt.scatter(Xi[:, 0], Xi[:, 1], s=5, alpha=.6, c=plt.cm.Accent(assignment))
plt.gca().set_aspect("equal")
plt.xticks(())
plt.yticks(())
plt.contour(xx, yy, scores.reshape(xx.shape), levels=np.logspace(0, 1, 20))
plt.title("Log vraisemblance négative prédite \n par le modèle")
plt.tight_layout()
Evaluation de méthodes#
L’évaluation d’une méthode de classification non supervisée n’est pas chose aisée, contrairement à des méthodes supervisées où un ensemble de test et un ensemble de validation permettent de calculer et de caractériser numériquement une solution.
Plusieurs aspects rentrent en jeu lorsqu’il s’agit de caractériser une partition d’un ensemble \(X=\left \{\mathbf x_i,i\in[\![1,n]\!] \right \}\):
Existe t il réellement une structure en nuage de points dans les données \(X\) ?
Si oui, quel est le nombre de classes ?
Comment évaluer la qualité d’une partition ?
Comment comparer deux partitions ?
Les mesures de qualité d’une partition peuvent être :
complètement non supervisées (ne s’appuyer sur aucune information externe) : on distingue ici les mesures de cohésion d’un nuage de points, et de séparation des nuages de points. On trouve aussi les indices se basant sur la matrice de proximité.
supervisées, qui vérifient à quel point une partition est conforme à une consigne extérieure. L’entropie est un exemple de mesure de ce type
relatives, qui permettent de comparer différentes partitions, ou nuages individuels.
Indices de silhouette#
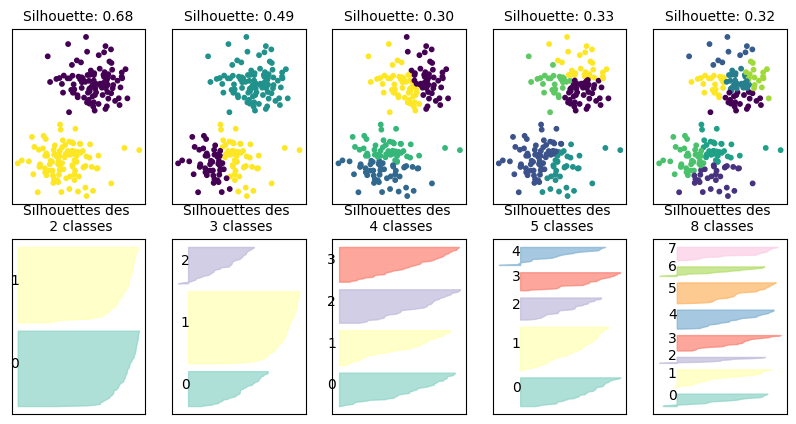
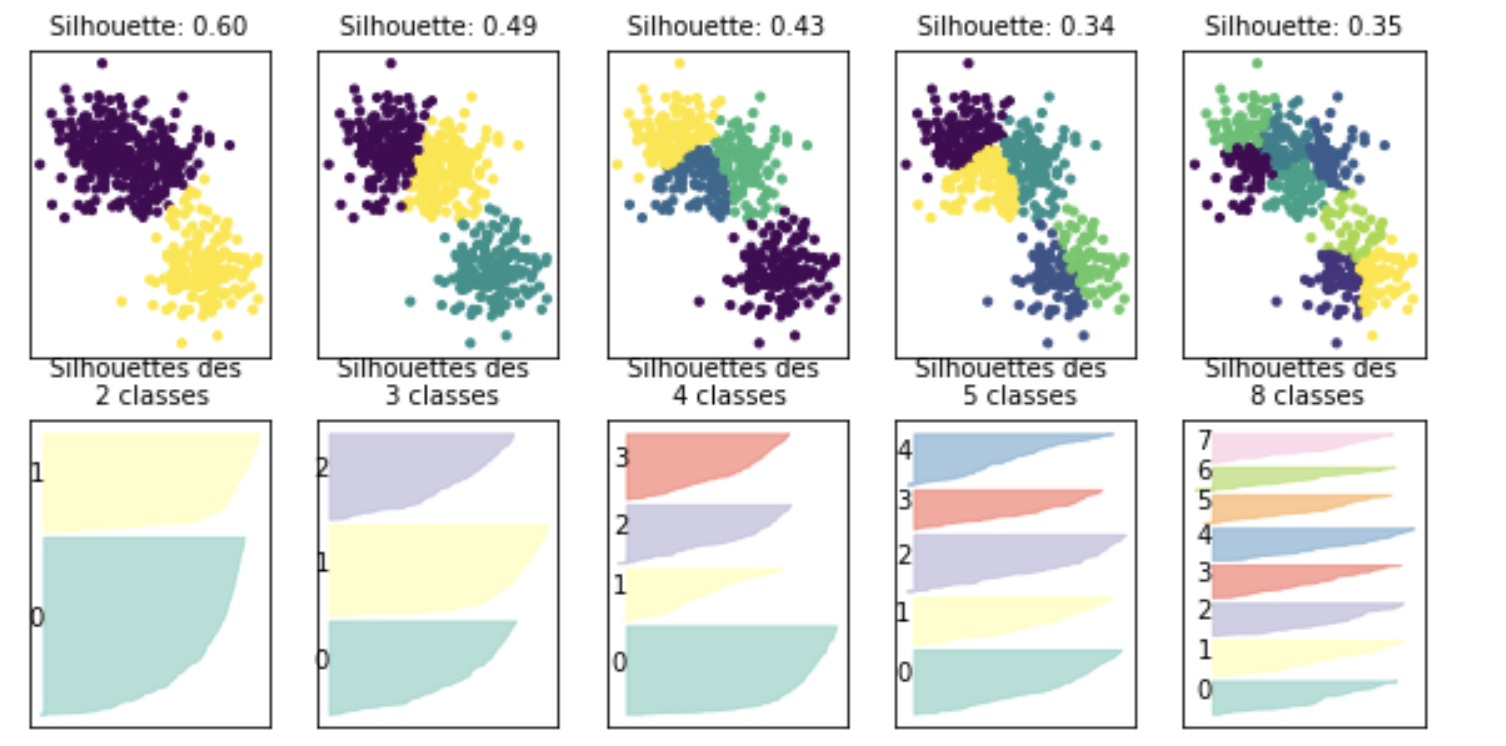
Un indice classiquement utilisé pour évaluer une partition issue de classification non supervisée est l’indice de silhouette (calculé sur un point de données, ou sur la partition entière).
Cet indice se calcule en trois étapes, illustrées dans le cas d’un point \(\mathbf x_i\) appartenant à la classe \(\mathcal{P}\) :
calcul de la distance moyenne de \(\mathbf x_i\) à chaque \(\mathbf x_j\) de sa classe \(\mathcal{P}\) : \(a_i = \frac{1}{|\mathcal{P}|-1}\displaystyle\sum_{\mathbf x_j\in \mathcal{P}} d(\mathbf x_i,\mathbf x_j)\)
pour une classe \(P_j\) ne contenant pas \(\mathbf x_i\), calcul de la distance moyenne de \(\mathbf x_i\) à tous les points de \(P_j\) : \(b_i = \frac{1}{|P_j|}\displaystyle\sum_{\mathbf x_k\in P_j} d(\mathbf x_i,\mathbf x_k)\)
calcul de l’indice de silhouette de \(\mathbf x_i\) : \(s_i = \frac{b_i-a_i}{max(a_i,b_i)}\).
On a clairement \(s_i\in[-1,1]\). De plus \(s_i<0\) signifie que \(a_i>b_i\) ce qui ne correspond pas à une situation acceptable pour une bonne partition. \(s_i\) doit donc être positif, et \(a_i\) le plus proche possible de 0 (pour avoir \(s_i\approx 1\)).
Une analyse fine peut être effectuée par nuage de points, à l’aide de l’indice de silhouette. A partir des indices de silhouette individuels, il est possible de calculer les indices des classes \(P_j\) (par moyenne des indices des points de la classe), et de la partition \(P\) (par moyenne des indices des classes \(P_j\)).
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
def silhouette_plot(X, cluster_labels, ax=None):
silhouette_scores = silhouette_samples(X, cluster_labels)
if ax is None:
ax = plt.gca()
y_lower = 10
inliers = cluster_labels != -1
X = X[inliers]
cluster_labels = cluster_labels[inliers]
silhouette_scores = silhouette_scores[inliers]
labels = np.unique(cluster_labels)
cm = plt.cm.Set3
for i in labels:
ith_cluster_silhouette_values = \
silhouette_scores[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm(i)
ax.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
ax.set_title("Silhouettes des \n {:d} classes".format(i+1),fontsize=10)
y_lower = y_upper + 10
Xblobs, yblobs = make_blobs(n_samples=200,n_features=2,centers=2,random_state=2,cluster_std=1.5,)
plt.scatter(Xblobs[:, 0], Xblobs[:, 1], c=yblobs, s=30, cmap='RdBu');
fig, axes = plt.subplots(2, 5, subplot_kw={'xticks': (), 'yticks':()}, figsize=(10, 5))
for ax, n_clusters in zip(axes.T, [2, 3, 4, 5, 8]):
km = KMeans(n_clusters=n_clusters)
km.fit(Xblobs)
ax[0].scatter(Xblobs[:, 0], Xblobs[:, 1], c=km.labels_, s=10)
silhouette_plot(Xblobs, km.labels_, ax=ax[1])
ax[0].set_title("Silhouette: {:.2f}".format(silhouette_score(Xblobs, km.labels_)),fontsize=10)
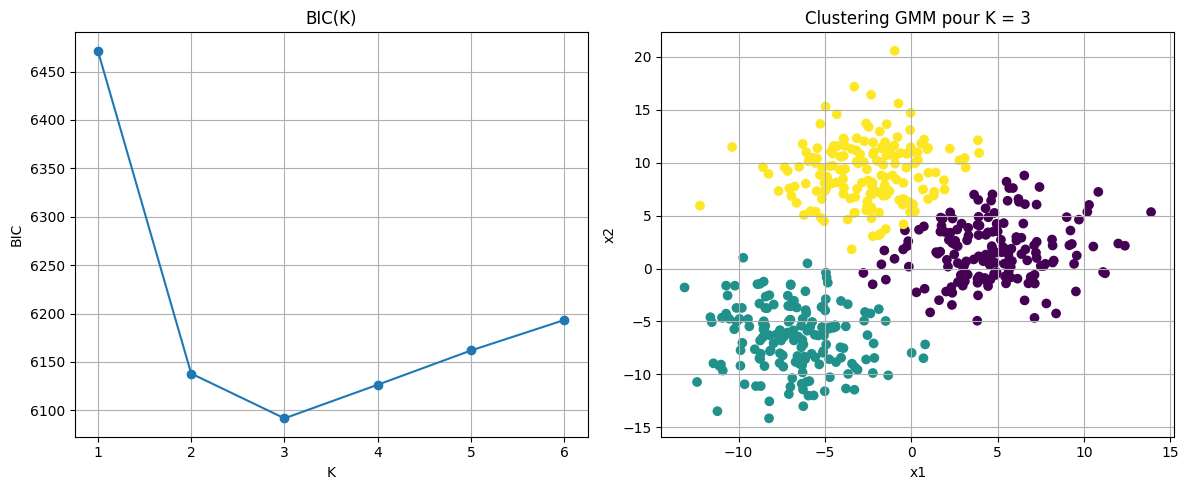
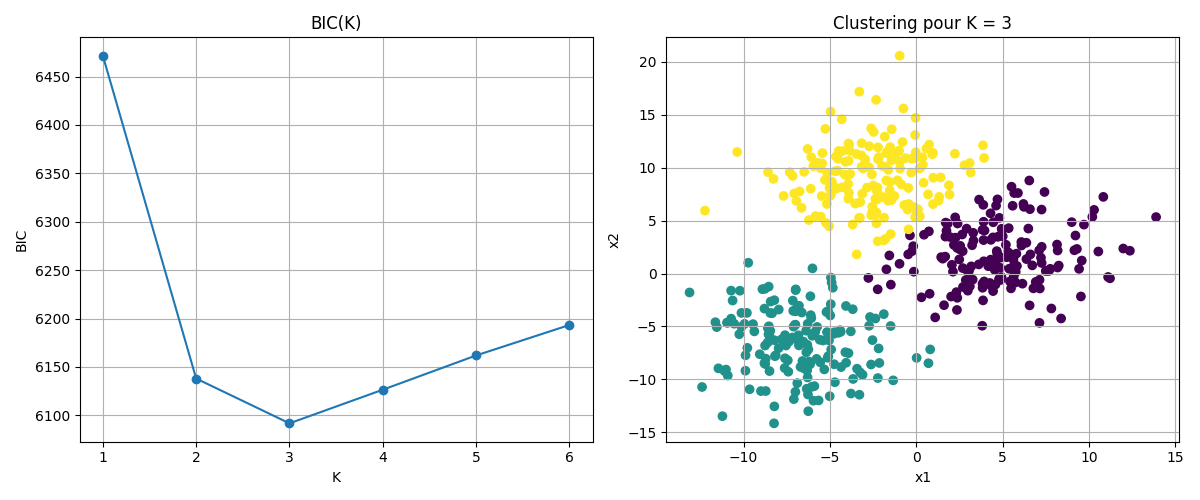
Bayesian Information Criterion#
Le critère BIC (Bayesian Information Criterion) est une mesure utilisée pour comparer des modèles statistiques, en particulier dans les méthodes d’apprentissage non supervisé. L’objectif est de trouver un compromis entre la qualité de l’ajustement aux données et la complexité du modèle. Contrairement à la simple maximisation de la vraisemblance, qui favorise toujours les modèles les plus complexes, le BIC pénalise les modèles comportant un trop grand nombre de paramètres, afin de réduire le risque de surapprentissage (overfitting).
Pour illustrer le critère, on considère un jeu de données \(X=\left \{\mathbf x_i,i\in[\![1,n]\!],\mathbf x_i\in\mathbb R^d \right \}\) généré à partir de trois groupes distincts de points, chacun correspondant à une distribution gaussienne centrée différemment.
On souhaite ajuster un modèle de mélange de gaussiennes sur ces données pour les regrouper en classes, sans connaître à l’avance le nombre réel de classes. Pour cela, on entraîne plusieurs modèles avec un nombre de composantes \(K\in [1,5]\) et pour chaque modèle on calcule :
la log-vraisemblance maximisée \(ln(\hat{K}_K)\)
le nombre de paramètres \(k_K = K\left (d+\frac{d(d+1)}{2} \right )+(K-1)\)
le BIC : \(BIC_K = -2ln(\hat{K}_K) +k_K ln(n)\)
Le code suivant propose un exemple.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=500, centers=3, cluster_std=3.0, random_state=42)
# Liste des valeurs de K à tester
K_range = range(1, 7)
bics = []
log_likelihoods = []
for K in K_range:
gmm = GaussianMixture(n_components=K, covariance_type='full', random_state=42)
gmm.fit(X)
bics.append(gmm.bic(X))
# Log-vraisemblance
log_likelihoods.append(gmm.score(X) * X.shape[0])
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
ax[0].plot(K_range, bics, marker='o')
ax[0].set_title("BIC(K)")
ax[0].set_xlabel("K")
ax[0].set_ylabel("BIC")
ax[0].grid(True)
optimal_K = K_range[np.argmin(bics)]
gmm_optimal = GaussianMixture(n_components=optimal_K, covariance_type='full', random_state=42)
y_gmm = gmm_optimal.fit_predict(X)
ax[1].scatter(X[:, 0], X[:, 1], c=y_gmm)
ax[1].set_title(f"Clustering GMM pour K = {optimal_K}")
ax[1].set_xlabel("x1")
ax[1].set_ylabel("x2")
ax[1].grid(True)
plt.tight_layout()
plt.show()
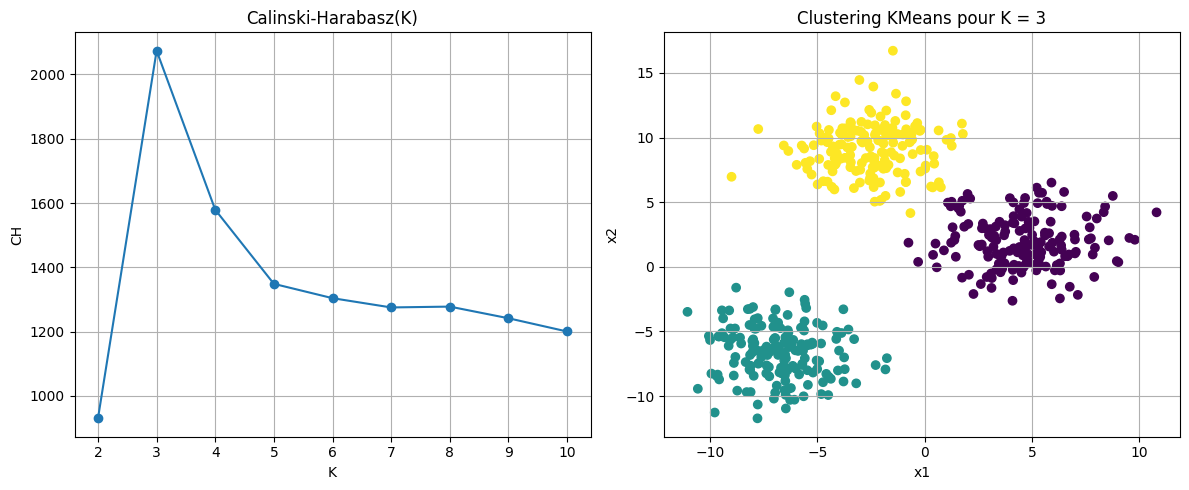
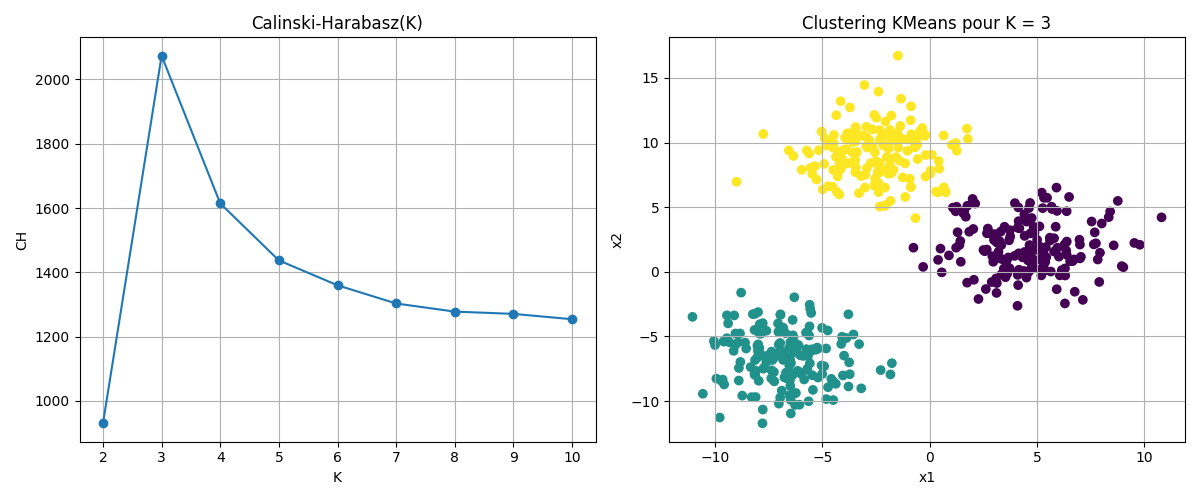
Indice de Calinski-Harabasz#
L’indice de Calinski-Harabasz est un indice simple, égal au rapport entre la variance inter-groupes et la variance intra-groupe.
Considérons un ensemble de données \(X = \{\mathbf x_1, \dots, \mathbf x_n\} \subset \mathbb{R}^d\), partitionné en \(k\) clusters. Soit \(\mathbf c_i\) le centroïde du \(i\)-ème cluster, \(\mathbf c\) le centroïde global de l’ensemble des données, \(n_i\) le nombre d’observations dans le \(i\)-ème cluster. On définit alors la matrice de dispersion inter-classe \(\mathbf B_k\) et la matrice de dispersion intra-classe \(\mathbf W_k\) comme suit :
L’indice de Calinski-Harabasz est alors donné par :
Ce rapport exprime la séparation (numerateur) normalisée par la compacité (dénominateur) en tenant compte du nombre de groupes. L’indice atteint généralement un maximum pour une valeur optimale du nombre de clusters \(k\).
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
X, y_true = make_blobs(n_samples=500, centers=3, cluster_std=2.0, random_state=42)
K_range = range(2, 11)
ch_scores = []
for K in K_range:
kmeans = KMeans(n_clusters=K, random_state=42)
labels = kmeans.fit_predict(X)
score = calinski_harabasz_score(X, labels)
ch_scores.append(score)
optimal_K_ch = K_range[np.argmax(ch_scores)]
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
ax[0].plot(K_range, ch_scores, marker='o')
ax[0].set_title("Calinski-Harabasz(K)")
ax[0].set_xlabel("K")
ax[0].set_ylabel("CH")
ax[0].grid(True)
kmeans_optimal = KMeans(n_clusters=optimal_K_ch, random_state=42)
labels_optimal = kmeans_optimal.fit_predict(X)
ax[1].scatter(X[:, 0], X[:, 1], c=labels_optimal)
ax[1].set_title(f"Clustering KMeans pour K = {optimal_K_ch}")
ax[1].set_xlabel("x1")
ax[1].set_ylabel("x2")
ax[1].grid(True)
plt.tight_layout()
plt.show()
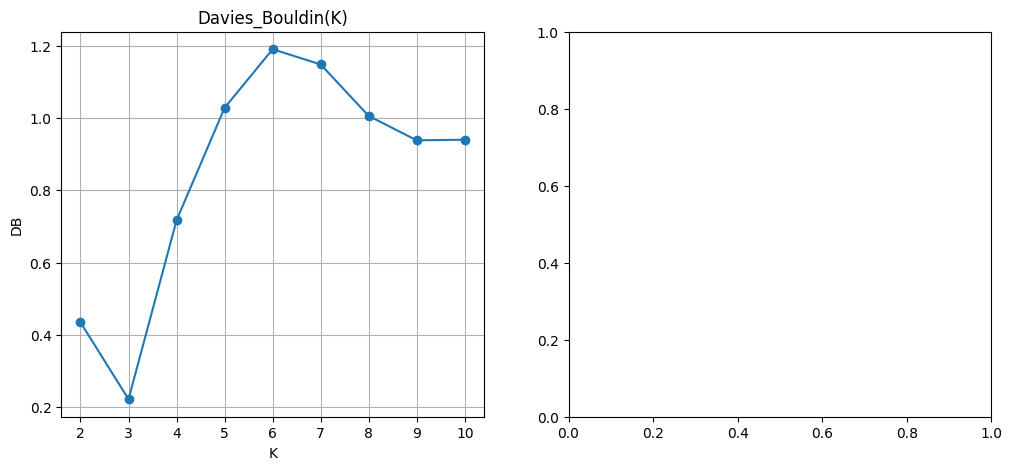
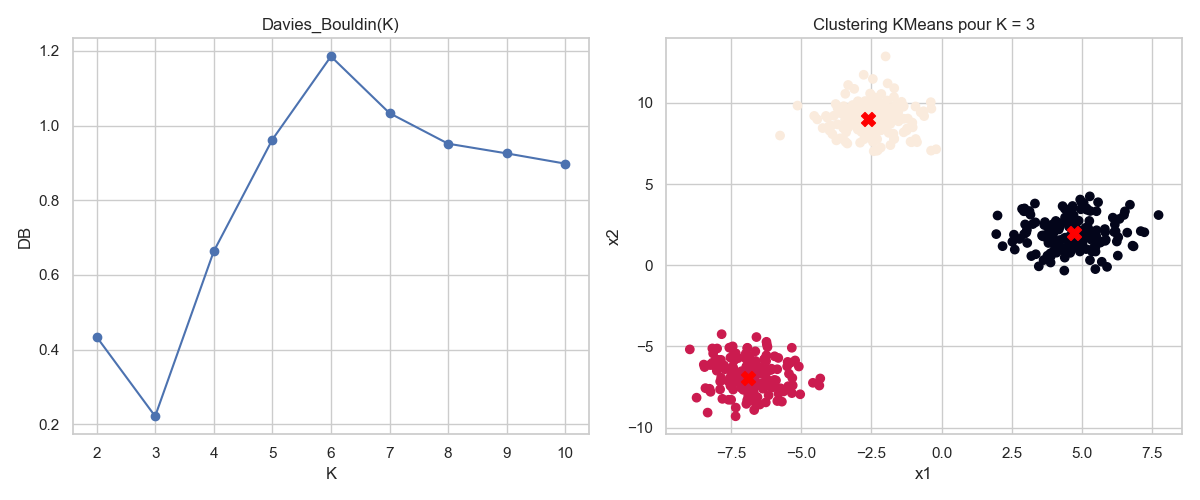
Indice de Davies-Bouldin#
Avec les mêmes notations que précédemment, pour chaque cluster \(C_i\), on définit \(\mathbf c_i\) comme son centroïde, et \(s_i\) comme une mesure de dispersion intra-classe, par exemple :
On calcule ensuite, pour chaque paire \((i,j)\) avec \(i \ne j\), une mesure de similarité entre les clusters \(C_i\) et \(C_j\) :
L’indice de Davies-Bouldin est alors défini comme la moyenne, pour chaque cluster \(C_i\), de la plus grande similarité avec un autre cluster :
Cette formulation incite à rechercher des clusters à la fois compacts (valeurs \(s_i\) faibles) et bien séparés (valeurs \(\|\mathbf c_i - \mathbf c_j\|\) élevées). L’indice est particulièrement utile pour comparer plusieurs partitions obtenues avec des paramètres ou des méthodes différents. Un minimum local de l’indice peut indiquer un bon compromis entre cohésion interne et séparation externe des groupes.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import davies_bouldin_score
X, y_true = make_blobs(n_samples=500, centers=3, cluster_std=1.0, random_state=42)
K_range = range(2, 11)
db_scores = []
for K in K_range:
kmeans = KMeans(n_clusters=K, random_state=42)
labels = kmeans.fit_predict(X)
score = davies_bouldin_score(X, labels)
db_scores.append(score)
optimal_K_db = K_range[np.argmin(db_scores)]
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
ax[0].plot(K_range, db_scores, marker='o')
ax[0].set_title("Davies_Bouldin(K)")
ax[0].set_xlabel("K")
ax[0].set_ylabel("DB")
ax[0].grid(True)
kmeans_optimal = KMeans(n_clusters=optimal_K_db, random_state=42)
labels_optimal = kmeans_optimal.fit_predict(X)
centroids = kmeans_best.cluster_centers_
ax[1].scatter(X[:, 0], X[:, 1], c=labels_optimal)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=100, marker='X', label='Centroïdes')
ax[1].set_title(f"Clustering KMeans pour K = {optimal_K_db}")
ax[1].set_xlabel("x1")
ax[1].set_ylabel("x2")
ax[1].grid(True)
plt.tight_layout()
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[18], line 30
28 kmeans_optimal = KMeans(n_clusters=optimal_K_db, random_state=42)
29 labels_optimal = kmeans_optimal.fit_predict(X)
---> 30 centroids = kmeans_best.cluster_centers_
32 ax[1].scatter(X[:, 0], X[:, 1], c=labels_optimal)
33 plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=100, marker='X', label='Centroïdes')
NameError: name 'kmeans_best' is not defined