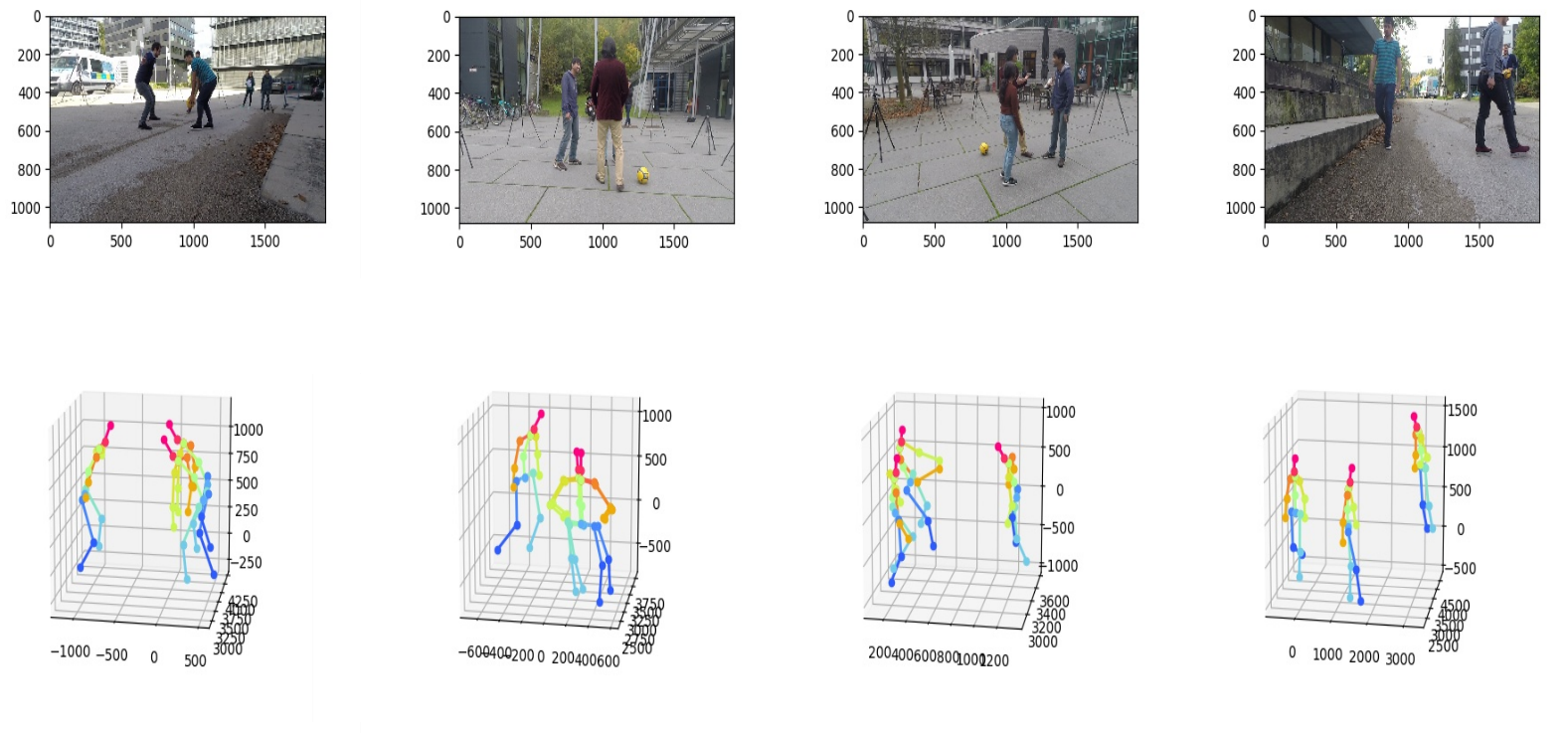
Deep Learning based 3D Multi-person Human pose estimation from Monocular Vision
2D multi-person pose estimation and 3D root-relative pose estimation from a monocular RGB camera have made significant progress recently. Yet real-world applications require depth estimation and the ability to determine the distance between people in the scene. Therefore, it is necessary to recover the 3D absolute poses of several people. However, this is still a challenge when using cameras from a single point of view. In this work, we propose a real-time framework that hybrids models in the top-down scheme for 3D multi-person absolute pose estimation from a monocular camera. We compared three different strategies proposed to obtain the final poses. Two of them integrate human bounding boxes detector, 2D pose estimator, 3D root-relative pose reconstructor and root depth estimator. The other one uses a 3D absolute pose estimator directly after the estimation of 2D points. We evaluate our system called Root-GastNet on the root joint localization with two benchmark datasets, i.e., Human3.6M and MuPoTS-3D. The experimental results show that all three strategies outperform the state-of-the-art on the MuPoTS-3D dataset. Moreover, it could be applied in real-time.
Modular Ensemble tracking
Numerous works identify object tracking as a critical issue in many applications such as surveillance and anomaly detection. Among all definitions, the simplest but clearest one defines tracking as the estimation from a video sequence of the trajectory of moving object in the image plane. The tracking by itself is composed of two steps : an object detection step, where potential candidates are identified in each frame of the sequence, and a tracking step, where a specific candidate is tracked all along the frames. Depending on the constraints imposed on these two steps, several methods and algorithms are available.
We imposed four constraints : we wanted the tracker to be (i) robust (ii) real-time (iii) able to track pedestrians and (iv) usable from mobile cameras acquisitions. Considering these four points, numerous tracking methods are available, that can be separated into four main categories. Background subtraction, silhouette tracking, points tracking and supervised learning methods. Due to constraints (iii), the -first two ones are inappropriate and we focused on the remaining two other categories.
We proposed to have a double point of view, by combining Point tracking and supervised learning methods into a modular version of the Ensemble Tracking Algorithm (MET). Classifiers were trained with Adaboost on homogeneous feature spaces, and the classification decisions were used by a particle filter specially designed for the application.
The MET algorithm is based on two ideas. The main drawback of the classical Ensemble Tracking algorithm relies on the definition of its strong classifier, since each weak classifier works on an heterogeneous feature space. We thus decided to split this feature space into several homogeneous subspaces (called modules) where a strong classifier lives and takes a decision on the position of the object to tracking is computed. Splitting the feature space strongly modifies the objective of the tracking process : a tracking algorithm now has to estimate a hidden state composed on the one hand of the position and the dimensions of the object, and on the other hand of the linear weights of the decisions, leading to the most discriminant observation. The second modification we proposed, resolving this second objective, was based on the construction of a specific particle filter jointly managing both the positions and dimensions of the object and the weights of the modules.
Tracking on a mobile camera

Scaling on a camera with mobile optical center
